zvažte případ, kdy jste vytvořili funkce, víte o důležitosti funkcí a máte vytvořit klasifikační model, který má být prezentován ve velmi krátkém časovém období?
Co budete dělat? Máte velmi velký objem datových bodů a velmi méně málo funkcí v datové sadě., V této situaci pokud bych měl takový model bych použil ‚Naivní Bayes‘, která je považována za opravdu rychlý algoritmus, pokud jde o klasifikaci úkolů.
v tomto blogu se snažím vysvětlit, jak funguje algoritmus, který lze použít v těchto typech scénářů. Pokud chcete vědět, co je klasifikace a další takové algoritmy, můžete se podívat zde.
Naive Bayes je model strojového učení, který se používá pro velké objemy dat, i když pracujete s daty, která mají miliony datových záznamů, doporučený přístup je naivní Bayes., Poskytuje velmi dobré výsledky, pokud jde o úkoly NLP, jako je sentimentální analýza. Jedná se o rychlý a nekomplikovaný klasifikační algoritmus.
abychom pochopili naivní Bayesův klasifikátor, musíme pochopit Bayesovu větu. Takže pojďme nejprve diskutovat Bayesovu větu.
Bayesova věta
je to věta, která pracuje na podmíněné pravděpodobnosti. Podmíněná pravděpodobnost je pravděpodobnost, že se něco stane, vzhledem k tomu, že již došlo k něčemu jinému. Podmíněná pravděpodobnost nám může dát pravděpodobnost události pomocí jejích předchozích znalostí.,
Podmíněná pravděpodobnost:
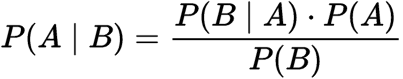
Podmíněná Pravděpodobnost
Kde:
P(A): pravděpodobnost, Že hypotéza H je pravda. Toto je známé jako předchozí pravděpodobnost.
P(B): pravděpodobnost důkazů.
P (A / B): pravděpodobnost důkazů vzhledem k tomu, že hypotéza je pravdivá.
P (B / A): pravděpodobnost hypotézy vzhledem k tomu, že důkaz je pravdivý.
Naive Bayes Classifier
-
jedná se o druh klasifikátoru, který pracuje na Bayesově teorému.,
-
predikce pravděpodobnosti členství se provádí pro každou třídu, jako je pravděpodobnost datových bodů spojených s určitou třídou.
-
třída s maximální pravděpodobností je hodnocena jako nejvhodnější třída.
- toto je také označováno jako Maximum a Posteriori (mapa).
-
NB klasifikátory k závěru, že všechny proměnné nebo funkce nejsou vzájemně souvisí.
-
Existence nebo nepřítomnost proměnné nemá vliv na existenci nebo nepřítomnost jiné proměnné.,
-
Příklad:
-
Ovoce může být pozorován být jablko, pokud je červené, kulaté, a asi 4″ v průměru.
-
V tomto případě také, i když všechny funkce jsou vzájemně propojeny navzájem, a NB klasifikátor bude sledovat všechny z nich nezávisle přispívá k pravděpodobnosti, že ovoce je jablko.
-
-
experimentujeme s hypotézou v reálných datových sadách, vzhledem k více funkcím.
-
takže výpočet se stává složitým.
typy naivních Bayesových algoritmů
1., Gaussova Naivní Bayes: Když charakteristické hodnoty jsou spojité v přírodě pak předpoklad, že hodnoty spojené s každou třídu jsou rozptýleny podle Gaussova, že je Normální Rozdělení.
2. Multinomiální naivní Bayes: multinomiální naivní Bayes je upřednostňován pro použití na datech, která jsou distribuována multinomiálně. To je široce používán v klasifikaci textu v NLP. Každá událost v klasifikaci textu představuje přítomnost slova v dokumentu.
3., Bernoulli Naïve Bayes: když jsou data vydávána podle multivariačních distribucí Bernoulli, použije se Bernoulli Naive Bayes. To znamená, že existuje více funkcí, ale předpokládá se, že každá obsahuje binární hodnotu. Takže vyžaduje, aby funkce byly binární.
výhody a nevýhody naivních Bayes
výhody:
-
Jedná se o vysoce rozšiřitelný algoritmus, který je velmi rychlý.
-
může být použit jak pro Binary, tak pro klasifikaci multiclass.,
-
má hlavně tři různé typy algoritmů, které jsou GaussianNB, MultinomialNB, BernoulliNB.
-
jedná se o slavný algoritmus pro klasifikaci spamových e-mailů.
-
může být snadno vyškolen na malých datových sadách a může být použit i pro velké objemy dat.
nevýhody:
-
hlavní nevýhodou NB je zvažování všech nezávislých proměnných, které přispívají k pravděpodobnosti.,
aplikace naivních Bayesových algoritmů
-
Predikce v reálném čase: být algoritmem rychlého učení lze použít také k předpovídání v reálném čase.
-
klasifikace MultiClass: může být také použita pro klasifikační problémy s více třídami.
-
klasifikace textu: jak to ukázalo dobré výsledky při předpovídání klasifikace více tříd, takže má větší úspěšnost ve srovnání se všemi ostatními algoritmy. V důsledku toho se používá převážně v analýze sentimentu & detekce spamu.,
praktické Prohlášení o problému
problémovým prohlášením je klasifikace pacientů jako diabetických nebo nediabetických. Soubor dat lze stáhnout z webových stránek Kaggle, který je „Pima INDIAN DIABETES DATABASE“. Datové sady měly několik různých lékařských prediktorů a cíl, který je „výsledek“. Prediktorové proměnné zahrnují počet těhotenství, které pacient měl, jejich BMI, hladinu inzulínu, věk a tak dále.,
Kód provádění importu a rozdělení dat,
TAKTO-
- Zpočátku, všechny potřebné knihovny jsou importovány jako numpy, pandas, vlak-test_split, GaussianNB, metriky.
- Co to je datový soubor bez záhlaví, dodáme názvy sloupců, které byly získány z výše uvedené URL
- Vytvořil python seznam názvů sloupců nazývá „jména“.
- inicializované prediktorové proměnné a cíl, který je X a Y.
- transformovala data pomocí StandardScaler.,
- rozdělit data do tréninkových a testovacích sad.
- vytvořil objekt pro GaussianNB.
- vybavila data v modelu, aby je vycvičila.
- předpověděl testovací sadu a uložil ji do proměnné „prediktor“.
pro provádění průzkumné analýzy datového souboru můžete hledat techniky.

Zmatek-matrix & model skóre testovací data
- Importované accuracy_score a confusion_matrix z sklearn.metrik., Vytiskl matici zmatku mezi předpovězenou a skutečnou, která nám říká skutečný výkon modelu.
- vypočítal model_score testovacích dat, aby věděl, jak dobrý je model při zobecnění dvou tříd, které vyšly na 74%.,
model_score = model.score(X_test, y_test)model_score

Hodnocení modelu

Roc_score
- Importované auc, roc_curve znovu od sklearn.metrik.
- tištěné skóre roc_auc mezi falešně pozitivním a skutečným pozitivním, které vyšlo na 79%.
- importovaný matplotlib.pyplot knihovna vykreslit roc_curve.
- vytiskl roc_curve.,
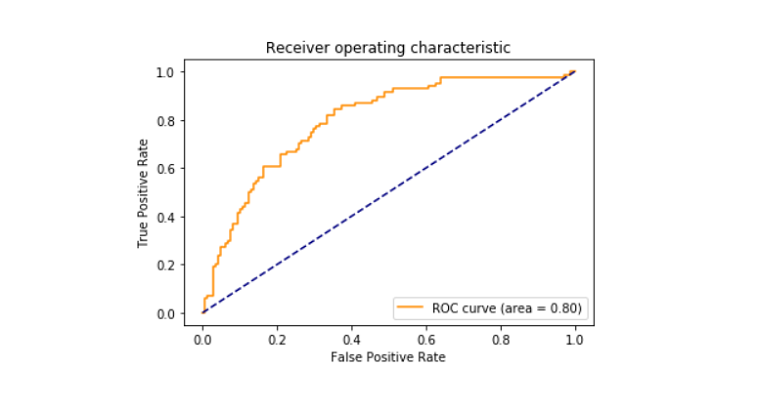
Roc_curve
přijímač provozní charakteristické křivky také známý jako roc_curve je děj, který vypráví o výklad potenciál binární klasifikátor systému. Je vykreslen mezi skutečnou pozitivní rychlostí a falešně pozitivní rychlostí při různých prahových hodnotách. Bylo zjištěno, že oblast křivky ROC je 0,80.
pro soubor python a také použitý datový soubor ve výše uvedeném problému můžete odkazovat na odkaz GitHub, který obsahuje oba.,
závěr
v tomto blogu jsem diskutoval o naivních bayesových algoritmech používaných pro klasifikační úkoly v různých kontextech. Mluvil jsem o tom, co je role Bayesova věta v NB Klasifikátor, různé vlastnosti NB, výhody a nevýhody NB, aplikace, NB, a v poslední, mám problém prohlášení z Kaggle, že je o klasifikaci pacientů jako diabetik, nebo ne.