fontolja meg egy olyan esetet, amikor létrehozott funkciókat, ismeri a funkciók fontosságát, és állítólag olyan osztályozási modellt kell készítenie, amelyet nagyon rövid idő alatt kell bemutatni?
mit fog tenni? Van egy nagyon nagy mennyiségű adat pontot, és nagyon kevésbé kevés funkciók az adathalmaz., Ebben a helyzetben, ha ilyen modellt kellett volna készítenem, “naiv Bayes” – t használtam volna, ezt nagyon gyors algoritmusnak tekintik, amikor osztályozási feladatokról van szó.
ebben a blogban megpróbálom elmagyarázni, hogyan működik az algoritmus, amely ilyen típusú forgatókönyvekben használható. Ha szeretné tudni, hogy mi az osztályozás és más ilyen algoritmusok itt hivatkozhat.
naiv Bayes egy gépi tanulási modell, amelyet nagy mennyiségű adathoz használnak, még akkor is, ha több millió adatrekorddal rendelkező adatokkal dolgozik, az ajánlott megközelítés naiv Bayes., Nagyon jó eredményeket ad, amikor az NLP feladatokról van szó, mint például a szentimentális elemzés. Ez egy gyors és egyszerű osztályozási algoritmus.
a naiv Bayes osztályozó megértéséhez meg kell értenünk a Bayes-tételt. Tehát először beszéljük meg a Bayes-tételt.
Bayes-tétel
Ez egy tétel, amely feltételes valószínűséggel működik. A feltételes valószínűség annak a valószínűsége, hogy valami történni fog, tekintettel arra, hogy valami más már megtörtént. A feltételes valószínűség megadhatja nekünk az esemény valószínűségét előzetes ismereteinek felhasználásával.,
Feltételes valószínűség:
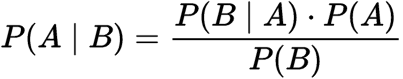
Feltételes valószínűség
ahol
p(A): a H hipotézis igazságának valószínűsége. Ez az úgynevezett előzetes valószínűség.
p (B): a bizonyítékok valószínűsége.
P (A / B): a hipotézisre adott bizonyítékok valószínűsége igaz.
P (B / A): A hipotézis valószínűsége, mivel a bizonyítékok igazak.
naiv Bayes osztályozó
-
Ez egyfajta osztályozó, amely a Bayes tételen működik.,
-
a tagsági valószínűségek előrejelzése minden osztályra vonatkozik, például egy adott osztályhoz társított adatpontok valószínűségére.
-
a maximális valószínűségű osztály a legmegfelelőbb osztály.
- ez is nevezik Maximum A Posteriori (térkép).
-
NB osztályozók arra a következtetésre jutnak, hogy az összes változó vagy funkció nem kapcsolódik egymáshoz.
-
a változó létezése vagy hiánya nem befolyásolja más változó létezését vagy hiányát.,
-
példa:
-
gyümölcs lehet megfigyelni, hogy egy alma, ha piros, kerek, és körülbelül 4″ átmérőjű.
-
ebben az esetben akkor is, ha az összes funkció egymáshoz kapcsolódik, és NB osztályozó fogja megfigyelni ezeket függetlenül hozzájárul a valószínűsége, hogy a gyümölcs egy alma.
-
-
a hipotézist valós adatkészletekben kísérletezzük, több funkciót adva.
-
tehát a számítás összetetté válik.
naiv Bayes algoritmusok típusai
1., Gauss naiv Bayes: amikor a jellemző értékek folytonosak a természetben, akkor feltételezzük, hogy az egyes osztályokhoz kapcsolódó értékek Gaussian szerint oszlanak el, ami normális eloszlás.
2. Multinomiális naiv Bayes: multinomiális naiv Bayes kedvelt használni az adatokat, amelyek multinomiális elosztott. Széles körben használják a szöveges osztályozásban az NLP-ben. A szöveges osztályozás minden eseménye egy szó jelenlétét jelenti a dokumentumban.
3., Bernoulli naiv Bayes: amikor az adatokat a többváltozós Bernoulli disztribúciók szerint adják ki, akkor Bernoulli naiv Bayes-t használnak. Ez azt jelenti, hogy több funkció létezik, de mindegyik feltételezhetően bináris értéket tartalmaz. Tehát megköveteli, hogy a funkciókat binárisan értékeljék.
előnyei és hátrányai naiv Bayes
előnyök:
-
Ez egy nagyon bővíthető algoritmus, amely nagyon gyors.
-
mindkét binárishoz, valamint a többosztályos osztályozáshoz használható.,
-
Ez elsősorban három különböző típusú algoritmusok, amelyek GaussianNB, MultinomialNB, BernoulliNB.
-
Ez egy híres algoritmus spam e-mail besorolás.
-
Ez könnyen képzett kis adathalmazok és lehet használni a nagy mennyiségű adat is.
hátrányok:
-
az NB fő hátránya, hogy minden olyan változót függetlennek tekint, amely hozzájárul a valószínűséghez.,
naiv Bayes algoritmusok alkalmazásai
-
valós idejű előrejelzés: gyors tanulási algoritmus lehet használni a jóslatok valós idejű előrejelzésére is.
-
Többosztályos osztályozás: többosztályos osztályozási problémákhoz is használható.
-
Szövegosztályozás: mivel jó eredményeket mutatott a többosztályos osztályozás előrejelzésében, így több sikerességi arány van az összes többi algoritmushoz képest. Ennek eredményeként, ez elsősorban használt hangulat elemzés & spam felismerés.,
gyakorlati Problémamegállapítás
a probléma megállapítása a betegek diabéteszes vagy nem diabetesesnek minősítése. Az adatkészlet letölthető a Kaggle webhelyről, amely a “PIMA INDIAN DIABETES DATABASE”. Az adatkészleteknek számos különböző orvosi prediktor tulajdonságuk volt, és egy olyan cél, amely “eredmény”. A prediktor változók közé tartozik a páciens terhességének száma, BMI-je, inzulinszintje, életkora stb.,
az adatok importálásának és megosztásának kódja
lépések –
- kezdetben az összes szükséges könyvtárat importálják, mint a numpy, pandas, train-test_split, GaussianNB, metrikák.
- mivel ez egy fejléc nélküli adatfájl, megadjuk a fenti URL-ből kapott oszlopneveket
- létrehozott egy “nevek”nevű oszlopnevek python listáját.
- inicializált prediktorváltozók, illetve a cél, amely X, illetve Y.
- átalakította az adatokat StandardScaler.,
- az adatokat képzési és tesztkészletekre osztjuk.
- létrehozott egy objektumot GaussianNB.
- az adatokat a modellbe illesztette, hogy kiképezze.
- jóslatokat készített a tesztkészletről, és egy “predictor” változóban tárolta.
az adatkészlet feltáró adatelemzésének elvégzéséhez keresse meg a technikákat.

&modell pontszám vizsgálati adatok
- importált accuracy_score és confusion_matrix sklearnból.mutatókat., Az előre jelzett és a tényleges közötti összetévesztési mátrixot kinyomtatta, amely megmutatja a modell tényleges teljesítményét.
- kiszámította a tesztelési adatok model_score-ját, hogy megtudja, mennyire jó a modell a két osztály általánosításában, amely 74% volt.,
model_score = model.score(X_test, y_test)model_score

a modell értékelése

roc_score
- importált AUC, roc_curve ismét sklearn.mutatókat.
- Printed roc_auc score between false positive and true positive that came out to be 79%.
- importált matplotlib.pyplot könyvtár telek a roc_curve.
- kinyomtatta a roc_curve-t.,
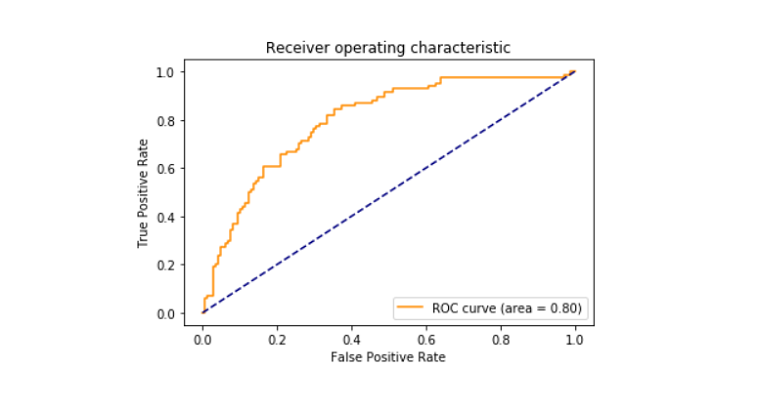
Roc_curve
a vevőkészülék működési jellemző görbéje is ismert, mint a roc_curve egy olyan cselekmény, amely egy bináris osztályozó rendszer értelmezési potenciáljáról szól. A valódi pozitív arány és a különböző küszöbértékek hamis pozitív aránya között van ábrázolva. A ROC görbe területe 0,80 volt.
a python fájlhoz, valamint a fenti probléma használt adatkészletéhez itt hivatkozhat a Github hivatkozásra, amely mindkettőt tartalmazza.,
következtetés
ebben a blogban a különböző kontextusokban osztályozási feladatokhoz használt naiv Bayes algoritmusokat tárgyaltam. Megbeszéltem, hogy mi a szerepe Bayes tétel NB osztályozó, különböző jellemzői NB, előnyei, hátrányai NB, alkalmazása NB, és az utolsó vettem egy probléma nyilatkozatot Kaggle, hogy körülbelül besorolása betegek diabéteszes vagy sem.