Considera un caso in cui hai creato funzionalità, conosci l’importanza delle funzionalità e dovresti creare un modello di classificazione che deve essere presentato in un periodo di tempo molto breve?
Cosa farai? Hai un volume molto grande di punti dati e molto meno poche funzionalità nel tuo set di dati., In quella situazione, se dovessi creare un modello del genere, avrei usato “Naive Bayes”, che è considerato un algoritmo molto veloce quando si tratta di compiti di classificazione.
In questo blog, sto cercando di spiegare come funziona l’algoritmo che può essere utilizzato in questo tipo di scenari. Se vuoi sapere cos’è la classificazione e altri algoritmi di questo tipo puoi fare riferimento qui.
Naive Bayes è un modello di apprendimento automatico che viene utilizzato per grandi volumi di dati, anche se si sta lavorando con i dati che ha milioni di record di dati l’approccio consigliato è Naive Bayes., Dà ottimi risultati quando si tratta di compiti PNL come l’analisi sentimentale. Si tratta di un algoritmo di classificazione veloce e semplice.
Per comprendere l’ingenuo classificatore di Bayes dobbiamo comprendere il teorema di Bayes. Quindi discutiamo prima il teorema di Bayes.
Teorema di Bayes
È un teorema che funziona sulla probabilità condizionale. La probabilità condizionale è la probabilità che qualcosa accada, dato che qualcos’altro è già accaduto. La probabilità condizionale può darci la probabilità di un evento usando la sua conoscenza precedente.,
Probabilità condizionale:
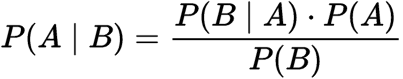
Probabilità condizionale
Dove,
P(A): La probabilità che l’ipotesi H sia vera. Questo è noto come la probabilità precedente.
P (B): La probabilità delle prove.
P (A / B): La probabilità della prova data che l’ipotesi è vera.
P (B / A): La probabilità dell’ipotesi dato che l’evidenza è vera.
Classificatore Naive Bayes
-
È un tipo di classificatore che funziona sul teorema di Bayes.,
-
La previsione delle probabilità di appartenenza viene effettuata per ogni classe, ad esempio la probabilità di punti dati associati a una particolare classe.
-
La classe con probabilità massima viene valutata come la classe più adatta.
- Questo è anche indicato come Massimo A Posteriori (MAPPA).
-
NB classificatori concludono che tutte le variabili o caratteristiche non sono correlati tra loro.
-
L’esistenza o l’assenza di una variabile non influisce sull’esistenza o l’assenza di qualsiasi altra variabile.,
-
Esempio:
-
La frutta può essere osservata come una mela se è rossa, rotonda e di circa 4″ di diametro.
-
In questo caso anche se tutte le caratteristiche sono correlate tra loro, e NB classificatore osserverà tutti questi indipendentemente contribuendo alla probabilità che il frutto è una mela.
-
-
Sperimentiamo l’ipotesi in set di dati reali, date molteplici funzionalità.
-
Quindi, il calcolo diventa complesso.
Tipi di algoritmi Naive Bayes
1., Bayes Naïve gaussiana: quando i valori caratteristici sono di natura continua, viene fatta un’ipotesi che i valori collegati a ciascuna classe siano dispersi secondo la distribuzione gaussiana che è Normale.
2. Multinomial Naïve Bayes: Multinomial Naive Bayes è favorito da utilizzare su dati distribuiti multinomiali. È ampiamente usato nella classificazione del testo in PNL. Ogni evento nella classificazione testuale costituisce la presenza di una parola in un documento.
3., Bernoulli Naïve Bayes: Quando i dati vengono erogati secondo le distribuzioni multivariate di Bernoulli, viene utilizzato Bernoulli Naïve Bayes. Ciò significa che esistono più funzionalità, ma si presume che ognuna contenga un valore binario. Quindi, richiede che le funzionalità siano a valore binario.
Vantaggi e svantaggi di Naive Bayes
Vantaggi:
-
Si tratta di un algoritmo altamente estensibile che è molto veloce.
-
Può essere utilizzato sia per i binari che per la classificazione multiclasse.,
-
Ha principalmente tre diversi tipi di algoritmi che sono GaussianNB, MultinomialNB, BernoulliNB.
-
È un famoso algoritmo per la classificazione delle e-mail di spam.
-
Può essere facilmente addestrato su piccoli set di dati e può essere utilizzato anche per grandi volumi di dati.
Svantaggi:
-
Lo svantaggio principale della NB è considerare tutte le variabili indipendenti che contribuiscono alla probabilità.,
Applicazioni di algoritmi Naive Bayes
-
Previsione in tempo reale: essendo un algoritmo di apprendimento veloce può essere utilizzato per fare previsioni in tempo reale pure.
-
Classificazione multiclasse: può essere utilizzato anche per problemi di classificazione multi-classe.
-
Classificazione del testo: poiché ha mostrato buoni risultati nella previsione della classificazione multi-classe, ha più tassi di successo rispetto a tutti gli altri algoritmi. Di conseguenza, viene utilizzato principalmente nell’analisi del sentiment & rilevamento dello spam.,
Hands-On Problem Statement
La dichiarazione del problema consiste nel classificare i pazienti come diabetici o non diabetici. Il set di dati può essere scaricato dal sito web di Kaggle che è “PIMA INDIAN DIABETES DATABASE”. I set di dati avevano diverse caratteristiche predittive mediche e un obiettivo che è “Risultato”. Le variabili predittive includono il numero di gravidanze che il paziente ha avuto, il loro BMI, il livello di insulina, l’età e così via.,
Implementazione del codice di importazione e suddivisione dei dati
STEPS –
- Inizialmente, vengono importate tutte le librerie necessarie come numpy, panda, train-test_split, GaussianNB, metrics.
- Poiché si tratta di un file di dati senza intestazione, forniremo i nomi delle colonne che sono stati ottenuti dall’URL sopra
- Creato un elenco python di nomi di colonne chiamato “nomi”.
- Variabili predittive inizializzate e il target rispettivamente X e Y.
- Trasformato i dati utilizzando StandardScaler.,
- Dividere i dati in formazione e set di test.
- Ha creato un oggetto per GaussianNB.
- Montato i dati nel modello per addestrarlo.
- Ha fatto previsioni sul set di test e lo ha memorizzato in una variabile “predittore”.
Per fare l’analisi esplorativa dei dati del set di dati è possibile cercare le tecniche.

Confusion-matrix & model score test data
- Imported accuracy_score and confusion_matrix da sklearn.metrica., Stampato la matrice di confusione tra previsto e reale che ci dice le prestazioni effettive del modello.
- Ha calcolato il model_score dei dati di test per sapere quanto è buono il modello nel generalizzare le due classi che sono risultate essere 74%.,
model_score = model.score(X_test, y_test)model_score

la Valutazione del modello

Roc_score
- Importato auc, roc_curve di nuovo da sklearn.metrica.
- Punteggio roc_auc stampato tra falso positivo e vero positivo che è risultato essere 79%.
- matplotlib importato.libreria pyplot per tracciare il roc_curve.
- Stampato il roc_curve.,
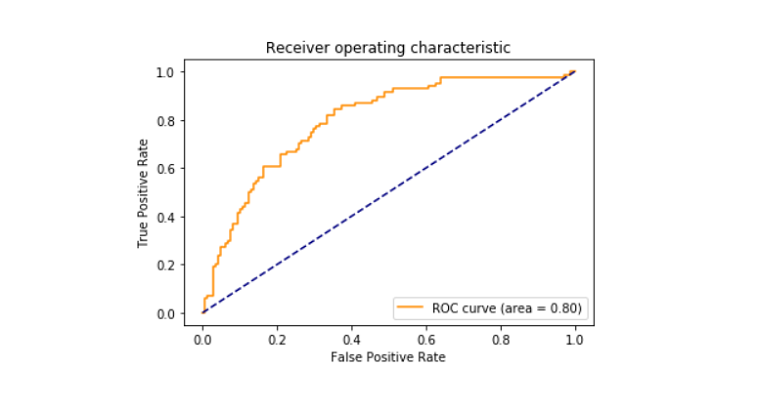
Roc_curve
La curva caratteristica di funzionamento ricevitore noto anche come roc_curve è una trama che racconta l’interpretazione potenziale di un classificatore binario di sistema. Viene tracciato tra il tasso vero positivo e il tasso falso positivo a soglie diverse. L’area della curva ROC è risultata essere 0,80.
Per il file python e anche il set di dati utilizzato nel problema precedente puoi fare riferimento al link Github qui che contiene entrambi.,
Conclusione
In questo blog, ho discusso ingenui algoritmi di Bayes utilizzati per le attività di classificazione in diversi contesti. Ho discusso qual è il ruolo del teorema di Bayes nel classificatore NB, diverse caratteristiche di NB, vantaggi e svantaggi di NB, applicazione di NB, e nell’ultimo ho preso una dichiarazione problematica da Kaggle che riguarda la classificazione dei pazienti come diabetici o meno.