Vurdere en sak der du har opprettet funksjoner, for du vet om betydningen av funksjoner og du er ment å gjøre en klassifisering modell som er til å bli presentert i en svært kort periode av tid?
Hva vil du gjøre? Du har et meget stort volum av data poeng og meget mindre noen funksjoner i datasettet., I denne situasjonen hvis jeg hadde å gjøre en slik modell ville jeg ha brukt «Naive Bayes’, som er ansett for å være en virkelig rask algoritme når det gjelder for klassifisering oppgaver.
I denne bloggen forsøker jeg å forklare hvordan algoritmen fungerer som kan brukes i slike situasjoner. Hvis du ønsker å vite hva som er klassifisering og andre slike algoritmer kan du se her.
Naive Bayes er en maskin læring modellen som er brukt for store volumer av data, selv om du arbeider med data som har millioner av datapostene er den anbefalte metoden er Naive Bayes., Det gir svært gode resultater når det kommer til NLP oppgaver som sentimental analyse. Det er en rask og ukomplisert klassifisering algoritme.
for Å forstå den naive Bayes classifier vi trenger å forstå Bayes teorem. Så la oss først diskutere Bayes Teorem.
Bayes Teorem
Det er et teorem som fungerer på betinget sannsynlighet. Betinget sannsynlighet er sannsynligheten for at noe vil skje, gitt at noe annet har allerede skjedd. Betinget sannsynlighet kan gi oss sannsynligheten for at en hendelse ved hjelp av sin tidligere kunnskap.,
Betinget sannsynlighet:
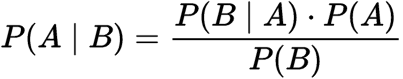
Betinget Sannsynlighet
Hvor
P(A): sannsynligheten for At hypotesen H å være sant. Dette er kjent som den tidligere sannsynlighet.
P(B): sannsynligheten for bevis.
P(A|B): sannsynligheten for bevis for gitt at hypotesen er sann.
P(B|A): sannsynligheten for At hypotesen gitt at bevisene er sant.
Naive Bayes Classifier
-
Det er en slags classifier som fungerer på Bayes teorem.,
-
logisk skriving av medlemskap sannsynligheter er gjort for hver klasse, slik som sannsynligheten av data poeng knyttet til en bestemt klasse.
-
klassen etter å ha maksimal sannsynlighet er avgrenset som den mest passende klasse.
- Dette er også omtalt som Maximum A Posteriori (KART).
-
NB classifiers konkludere med at alle variabler eller funksjoner som ikke er relatert til hverandre.
-
tilstedeværelsen eller fraværet av en variabel ikke påvirker forekomst eller fravær av andre variable.,
-
Eksempel:
-
Frukt kan observeres å være et apple-hvis det er rød, rund, og ca 4″ i diameter.
-
I dette tilfellet også selv om alle funksjoner er innbyrdes forhold til hverandre, og NB classifier vil observere alle av disse uavhengig bidra til sannsynligheten for at frukten er et eple.
-
-
Vi eksperimentere med hypotesen i reelle datasett, gitt flere funksjoner.
-
Så, beregning blir komplekse.
Typer Naive Bayes Algoritmer
1., Gaussian Naive Bayes: Når karakteristiske verdier er kontinuerlig i naturen da en forutsetning at verdiene knyttet til hver klasse er fordelt i henhold til Gaussian som er Normal Fordeling.
2. Multinomial Naive Bayes: Multinomial Naive Bayes er favoritt til å bruke på dataene som er multinomial fordelt. Det er mye brukt i teksten klassifisering i NLP. Hver hendelse i teksten klassifisering utgjør tilstedeværelsen av et ord i et dokument.
3., Bernoulli Naive Bayes: Når data er utlevert i henhold til den multivariate Bernoulli-distribusjoner så Bernoulli Naive Bayes er brukt. Det betyr at det finnes flere funksjoner, men hver og en er antatt å inneholde en binær verdi. Så, det krever funksjoner for å være binære verdsettes.
Fordeler Og Ulemper Av Naive Bayes
Fordeler:
-
Det er en svært utvidbar algoritme som er veldig rask.
-
Det kan brukes til både binærfiler samt multiclass klassifisering.,
-
Det er i hovedsak tre ulike former for algoritmer som er GaussianNB, MultinomialNB, BernoulliNB.
-
Det er en kjent algoritme for spam e-klassifisering.
-
Det kan være lett trent på små datasett, og kan brukes til store mengder data, så vel.
Ulemper:
-
Den viktigste ulempen med NB-er med tanke på alle de uavhengige variabler som bidrar til sannsynlighet.,
Programmer Naive Bayes Algoritmer
-
Real-time Prediksjon: å Være en rask læring algoritmen kan brukes til å gjøre forutsigelser i real-time, så vel.
-
MultiClass Klassifisering: Den kan brukes for å multi-klasse klassifisering problemer også.
-
Tekst Klassifisering: Som det har vist gode resultater i å forutsi multi-klasse klassifisering så det har mer suksess priser i forhold til alle de andre algoritmene. Som et resultat, det er majorly brukt i sentiment analysis & spam deteksjon.,
Hands-On Problem Uttalelse
problemet erklæringen er å klassifisere pasienter som diabetiker eller ikke-diabetiker. Datasettet kan lastes ned fra Kaggle nettsted som er «PIMA INDIAN DIABETES DATABASE’. Datasett hadde flere ulike medisinske prediktor funksjoner og et mål som er ‘Resultat’. Prediktor variabler inkluderer antall svangerskap pasienten har hatt, deres BMI, insulin nivå, alder og så videre.,
Kode implementering av import og dele data
TRINN-
– >
- første omgang, alle nødvendige biblioteker er importert som numpy, pandaer, tog-test_split, GaussianNB, beregninger.
- Siden det er en datafil med ingen overskrift, vil vi levere kolonnen navn som har blitt hentet fra den ovenfor URL
- Opprettet en python-liste over kolonnen navn som heter «navn».
- Initialisert prediktor variabler og målet er X og Y henholdsvis.
- Transformerte data ved hjelp av StandardScaler.,
- Split data til trening og test sett.
- Opprettet et objekt for GaussianNB.
- Utstyrt dataene i modellen for å trene det.
- Laget spådommer på test sett og lagret den i en «prediktor’ variabel.
For å gjøre den utforskende data analyse av dataset du kan se etter teknikker.

Forvirring-matrise & modell score test data
- Importerte accuracy_score og confusion_matrix fra sklearn.beregninger., Trykt forvirringen matrix mellom predikerte og faktiske som forteller oss at den faktiske ytelsen av modellen.
- Beregnet model_score av testing data til å vite hvor god er den modellen å opptre i generalisere de to klassene som kom ut til å være 74%.,
model_score = model.score(X_test, y_test)model_score

Evaluering av modellen

Roc_score
- Importerte auu, roc_curve igjen fra sklearn.beregninger.
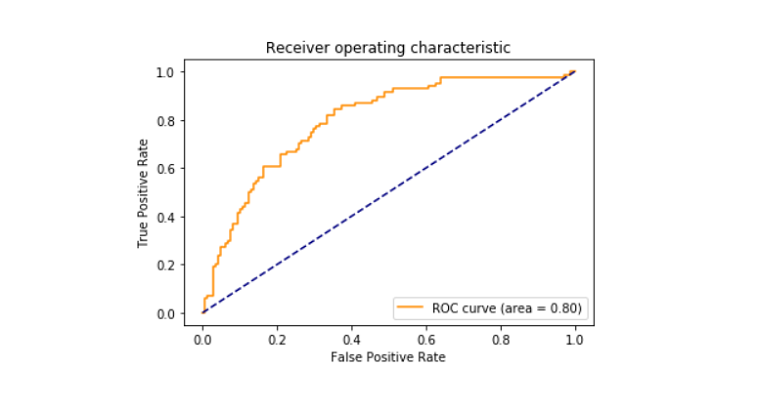
- Trykt roc_auc score mellom falske positive og sanne positive som kom ut for å være 79%.
- Importerte matplotlib.pyplot biblioteket for å plotte roc_curve.
- Trykte roc_curve.,
Roc_curve
receiver operating characteristic curve også kjent som roc_curve er en historie som forteller om tolkningen potensialet i en binær classifier system. Det er plottet mellom de sanne positive pris og falsk positiv rate på ulike terskler. ROC-kurve området ble funnet å være 0.80.
For python-fil og også datasettet som er brukt i over problemet, kan du henvise til Github link her som inneholder begge deler.,
Konklusjon
I denne bloggen, jeg har diskutert Naive Bayes algoritmer som brukes for klassifisering av oppgaver i ulike sammenhenger. Jeg har diskutert hva som er rollen som Bayes teorem i NB Classifier, ulike egenskaper av NB, fordeler og ulemper av NB, anvendelse av NB, og i det siste har jeg tatt et problem uttalelse fra Kaggle som er i ferd med å klassifisere pasienter som diabetes eller ikke.