overweeg een geval waarin u functies hebt gemaakt, u weet van het belang van functies en u wordt geacht een Classificatiemodel te maken dat in een zeer korte periode moet worden gepresenteerd?
wat gaat u doen? U heeft een zeer groot volume aan datapunten en zeer minder weinig functies in uw dataset., Als ik in die situatie zo ’n model moest maken zou ik’ Naive Bayes ‘ hebben gebruikt, dat wordt beschouwd als een heel snel algoritme als het gaat om classificatietaken.
in deze blog probeer ik uit te leggen hoe het algoritme werkt dat gebruikt kan worden in dit soort scenario ‘ s. Als u wilt weten wat is classificatie en andere dergelijke algoritmen kunt u hier verwijzen.
Naive Bayes is een machine learning model dat wordt gebruikt voor grote hoeveelheden data, zelfs als u werkt met data die miljoenen data records heeft de aanbevolen aanpak is Naive Bayes., Het levert zeer goede resultaten op als het gaat om NLP-taken zoals sentimentele analyse. Het is een snel en ongecompliceerd classificatiealgoritme.
om de naïeve Bayes classifier te begrijpen, moeten we de stelling van Bayes begrijpen. Laten we eerst de Stelling van Bayes bespreken.
Stelling van Bayes
Het is een stelling die werkt op voorwaardelijke kansrekening. Voorwaardelijke kans is de kans dat er iets zal gebeuren, gezien het feit dat er al iets anders is gebeurd. De voorwaardelijke waarschijnlijkheid kan ons de waarschijnlijkheid van een gebeurtenis geven met behulp van zijn voorkennis.,
voorwaardelijke kans:
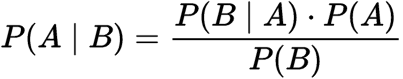
voorwaardelijke kans
waarbij,
P(A): de kans dat hypothese H waar is. Dit staat bekend als de voorafgaande waarschijnlijkheid.
P (B): de waarschijnlijkheid van het bewijs.
P (A / B): de waarschijnlijkheid van het bewijs gegeven deze hypothese is waar.
P (B / A): de waarschijnlijkheid van de hypothese gegeven dat het bewijs waar is.
Naive Bayes Classifier
-
Het is een soort classifier die werkt op de stelling van Bayes.,
-
voorspelling van ledenwaarschijnlijkheden wordt gemaakt voor elke klasse, zoals de waarschijnlijkheid van datapunten geassocieerd met een bepaalde klasse.
-
De klasse met maximale waarschijnlijkheid wordt beoordeeld als de meest geschikte klasse.
- Dit wordt ook wel Maximum a Posteriori (kaart) genoemd.
-
NB classifiers concluderen dat alle variabelen of kenmerken niet met elkaar verband houden.
-
het al dan niet bestaan van een variabele heeft geen invloed op het al dan niet bestaan van een andere variabele.,
-
voorbeeld:
-
Fruit kan worden waargenomen als een appel als het rood, rond, en ongeveer 4″ in diameter.
-
in dit geval ook als alle kenmerken met elkaar verbonden zijn, en NB classifier zal al deze onafhankelijk observeren en bijdragen aan de waarschijnlijkheid dat de vrucht een appel is.
-
-
we experimenteren met de hypothese in reële datasets, gegeven meerdere functies.
-
dus, berekening wordt complex.
typen naïeve Bayes-algoritmen
1., Gaussian naïeve Bayes: wanneer karakteristieke waarden continu van aard zijn dan wordt aangenomen dat de waarden verbonden met elke klasse worden verspreid volgens Gaussian dat is normale verdeling.
2. Multinomial naïeve Bayes: Multinomial naïeve Bayes is de voorkeur te gebruiken op gegevens die multinomial verdeeld. Het wordt veel gebruikt in tekstclassificatie in NLP. Elke gebeurtenis in tekstclassificatie vormt de aanwezigheid van een woord in een document.
3., Bernoulli naïeve Bayes: wanneer gegevens worden verstrekt volgens de multivariate Bernoulli distributies dan Bernoulli naïeve Bayes wordt gebruikt. Dat betekent dat er meerdere functies bestaan, maar elk ervan wordt verondersteld een binaire waarde te bevatten. Dus, het vereist functies binaire-gewaardeerd.
voor-en nadelen van naïeve Bayes
voordelen:
-
Het is een zeer snel uitbreidbaar algoritme.
-
het kan worden gebruikt voor zowel binaries als multiclass classificatie.,
-
het heeft voornamelijk drie verschillende soorten algoritmen die GaussianNB, MultinomialNB, BernoulliNB zijn.
-
het is een beroemd algoritme voor de classificatie van spam-e-mail.
-
het kan gemakkelijk worden getraind op kleine datasets en kan ook worden gebruikt voor grote hoeveelheden gegevens.
nadelen:
-
het belangrijkste nadeel van de NB is dat alle variabelen onafhankelijk worden beschouwd die bijdragen aan de waarschijnlijkheid.,
toepassingen van naïeve Bayes-algoritmen
-
Real-time voorspelling: een snell learning-algoritme zijn kan ook worden gebruikt om in real-time voorspellingen te doen.
-
MultiClass classificatie: Het kan ook worden gebruikt voor classificatieproblemen in meerdere klassen.
-
Tekstclassificatie: omdat het goede resultaten heeft laten zien in het voorspellen van classificatie in meerdere klassen, heeft het meer slagingspercentages in vergelijking met alle andere algoritmen. Als gevolg hiervan wordt het voornamelijk gebruikt in sentiment analyse & spam detectie.,
Hands-On Problem Statement
het probleem statement is om patiënten te classificeren als diabetisch of niet-diabetisch. De dataset kan worden gedownload van de Kaggle website die ‘Pima INDIAN DIABETES DATABASE’is. De datasets hadden verschillende medische voorspellende eigenschappen en een doel dat ‘resultaat’is. Voorspellende variabelen omvatten het aantal zwangerschappen de patiënt heeft gehad, hun BMI, insuline niveau, leeftijd, enzovoort.,
code implementatie van het importeren en splitsen van de gegevens
STEPS-
- aanvankelijk worden alle benodigde bibliotheken geïmporteerd zoals numpy, panda ‘ s, train-test_split, GaussianNB, metrics.
- omdat het een gegevensbestand is zonder header, zullen we de kolomnamen leveren die zijn verkregen uit de bovenstaande URL
- creëerde een python lijst met kolomnamen genaamd “names”.
- geïnitialiseerde voorspellende variabelen en het doel dat respectievelijk X en Y is.
- transformeerde de gegevens met behulp van StandardScaler.,
- splits de gegevens in trainings-en testsets.
- heeft een object gemaakt voor GaussianNB.
- paste de gegevens in het model om het te trainen.
- heeft voorspellingen gedaan op de testset en deze opgeslagen in een “predictor” – variabele.
Voor het uitvoeren van de verkennende gegevensanalyse van de dataset kunt u de technieken zoeken.

Confusion-matrix & model score testgegevens
- geïmporteerd accuracy_score en confusion_matrix van sklearn.metriek., Print de verwarmingsmatrix tussen voorspelde en werkelijke die ons de werkelijke prestaties van het model vertelt.
- berekende de model_score van de testgegevens om te weten hoe goed het model presteert in het veralgemenen van de twee klassen die uitkwamen op 74%.,
model_score = model.score(X_test, y_test)model_score

de Evaluatie van het model

Roc_score
- Geïmporteerde auc, roc_curve weer van sklearn.metriek.
- drukte de roc_auc-score af tussen false positive en true positive, die 79% bleek te zijn.
- geïmporteerde matplotlib.pyplot bibliotheek om de roc_curve te plotten.
- heeft de roc_curve afgedrukt.,
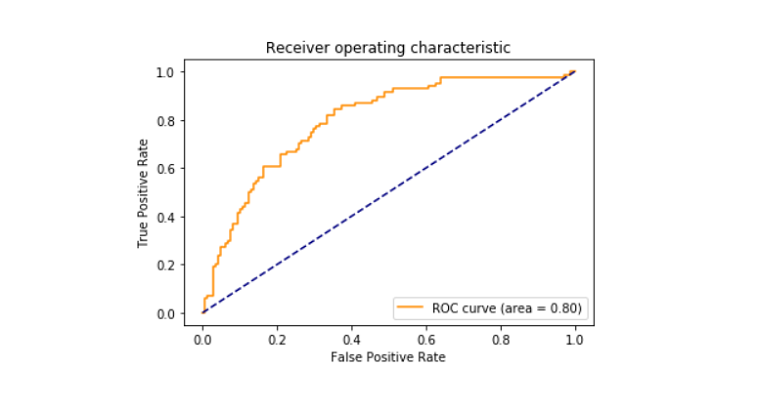
Roc_curve
over het interpretatiepotentieel van een binaire classificatiesysteem. Het wordt uitgezet tussen het werkelijke positieve percentage en het fout-positieve percentage bij verschillende drempels. Het ROC-curvegebied bleek 0,80 te zijn.
voor het python bestand en ook de gebruikte dataset in het bovenstaande probleem kunt u verwijzen naar de GitHub link hier die beide bevat.,
conclusie
in dit blog heb ik naïeve Bayes algoritmen besproken die gebruikt worden voor classificatietaken in verschillende contexten. Ik heb besproken wat is de rol van de stelling van Bayes in NB Classifier, verschillende kenmerken van NB, voordelen en nadelen van NB, toepassing van NB, en in de laatste heb ik een probleemverklaring van Kaggle dat is over het classificeren van patiënten als diabetische of niet genomen.