considere um caso em que você criou recursos, você sabe sobre a importância dos recursos e você deve fazer um modelo de classificação que deve ser apresentado em um período muito curto de tempo? o que vai fazer? Você tem um grande volume de pontos de dados e muito menos recursos em seu conjunto de dados., Nessa situação se eu tivesse que fazer tal modelo eu teria usado ‘ingênuo Bayes’, que é considerado um algoritmo realmente rápido quando se trata de tarefas de classificação.
neste blog, estou tentando explicar como o algoritmo funciona que pode ser usado neste tipo de cenários. Se você quiser saber o que é Classificação e outros algoritmos, você pode se referir aqui.
Ingenuble Bayes é um modelo de aprendizagem de máquina que é usado para grandes volumes de dados, mesmo se você está trabalhando com dados que tem milhões de registros de dados a abordagem recomendada é ingenuidade Bayes., Dá resultados muito bons quando se trata de Tarefas NLP, como a análise sentimental. É um algoritmo de classificação rápido e simples.
para entender o classificador ingênuo de Bayes precisamos entender o teorema de Bayes. Então vamos primeiro discutir o teorema de Bayes.
Teorema de Bayes
é um teorema que funciona com probabilidade condicional. Probabilidade condicional é a probabilidade de que algo aconteça, dado que algo mais já ocorreu. A probabilidade condicional pode nos dar a probabilidade de um evento usando seu conhecimento prévio.,
probabilidade Condicional:
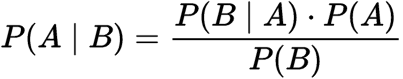
Probabilidade Condicional
Onde
P(A): A probabilidade de uma hipótese H de ser verdadeiro. Isto é conhecido como probabilidade prévia.
P(B): a probabilidade da evidência.
P(A / B): a probabilidade da evidência dada que a hipótese é verdadeira.
P (B / A): a probabilidade da hipótese dada de que a evidência é verdadeira.
ingênuo classificador de Bayes
-
é um tipo de classificador que trabalha no teorema de Bayes.,
-
a previsão de probabilidades de adesão é feita para cada classe, como a probabilidade de pontos de dados associados a uma determinada classe.a classe com probabilidade máxima é avaliada como a classe mais adequada.
- isto também é referido como máximo a Posteriori (mapa).
-
NB classificadores concluem que todas as variáveis ou características não estão relacionadas entre si.
-
a existência ou ausência de uma variável não afecta a existência ou ausência de qualquer outra variável.,
-
exemplo:
-
pode observar-se que os frutos são uma maçã se forem vermelhos, redondos e com cerca de 4″ de diâmetro.
-
neste caso também mesmo se todas as características estão inter-relacionadas entre si, e o classificador de NB irá observar todas estas independentemente contribuindo para a probabilidade de que o fruto é uma maçã.
-
-
experimentamos a hipótese em conjuntos de dados reais, dadas várias características.
-
assim, o cálculo torna-se complexo.
tipos de algoritmos ingênuos de Bayes
1., Bayes Naïve Gaussian: quando os valores característicos são de natureza contínua, então faz-se uma suposição de que os valores ligados a cada classe são dispersos de acordo com Gaussian que é a distribuição Normal.2. Multinomial Naïve Bayes: Multinomial Naive Bayes é favorecido para usar em dados que são distribuídos multinomial. É amplamente utilizado na classificação de texto em NLP. Cada evento na classificação de texto constitui a presença de uma palavra em um documento.3., Bernoulli Naïve Bayes: quando os dados são distribuídos de acordo com as distribuições multivariadas de Bernoulli então Bernoulli ingênuo Bayes é usado. Isso significa que existem várias características, mas cada uma é assumida para conter um valor binário. Então, requer recursos para serem avaliados binários.
vantagens e desvantagens de Bayes ingênuos
vantagens:
-
é um algoritmo altamente extensível que é muito rápido.
-
pode ser utilizado tanto para binários como para classificação multiclass.,
-
Ele tem, principalmente, três tipos diferentes de algoritmos que são GaussianNB, MultinomialNB, BernoulliNB.
-
é um algoritmo famoso para a classificação de email de spam.
-
pode ser facilmente treinado em pequenos conjuntos de dados e pode ser usado para grandes volumes de dados também.
Desvantagens:
-
A principal desvantagem do NB é, considerando todas as variáveis independentes que contribuem para a probabilidade.,
Applications of Naive Bayes Algorithms
-
Real-time Prediction: Being a fast learning algorithm can be used to make predictions in real-time as well.
-
classificação MultiClass: também pode ser usado para problemas de classificação multi-classes.
-
classificação de texto: como tem mostrado bons resultados na previsão de classificação multi-classes assim que tem mais taxas de sucesso em comparação com todos os outros algoritmos. Como resultado, é principalmente usado na análise de sentimentos & detecção de spam.,a declaração do problema é classificar os doentes como diabéticos ou não diabéticos. O conjunto de dados pode ser descarregado do sítio web do Kaggle que é a “base de dados de DIABETES Indiana PIMA”. Os conjuntos de dados tinham várias características de prognóstico médico diferentes e um alvo que é o “resultado”. As variáveis Predictor incluem o número de gravidezes que o paciente teve, seu IMC, nível de insulina, idade, e assim por diante.,
implementação de Código de importação e dividir os dados
PASSOS-
- Inicialmente, todas as bibliotecas necessárias são importados como numpy, pandas, trem-test_split, GaussianNB, métricas.
- Uma vez que é um ficheiro de dados sem cabeçalho, iremos fornecer os nomes das colunas que foram obtidos a partir do URL acima
- criou uma lista python de nomes de colunas chamadas “nomes”.
- variáveis de predictor inicializadas e o alvo que é X e Y respectivamente.
- transformou os dados usando Scaler padrão.,divide os dados em conjuntos de treino e ensaio.
- criou um objeto para GaussianNB.
- instalou os dados no modelo para treiná-lo.
- fez previsões sobre o conjunto de testes e armazenou-o numa variável de “predictor”.
para fazer a análise de dados exploratórios do conjunto de dados você pode procurar as técnicas.
Confusão-matriz & modelo de pontuação de teste de dados
- Importado accuracy_score e confusion_matrix de sklearn.metrica., Imprimiu a matriz de confusão entre predito e real que nos diz o desempenho real do modelo.
- calculou o model_score dos dados de teste para saber o quão bom é o modelo que se apresenta na generalização das duas classes que vieram a ser 74%.,
model_score = model.score(X_test, y_test)model_scorea Avaliação do modelo
Roc_score
- Importado auc, roc_curve novamente a partir sklearn.metrica.
- Printed roc_auc score between false positive and true positive that came to be 79%.matplotlib importado.biblioteca pyplot para desenhar a curva roc_curve.
- Printed the roc_curve.,
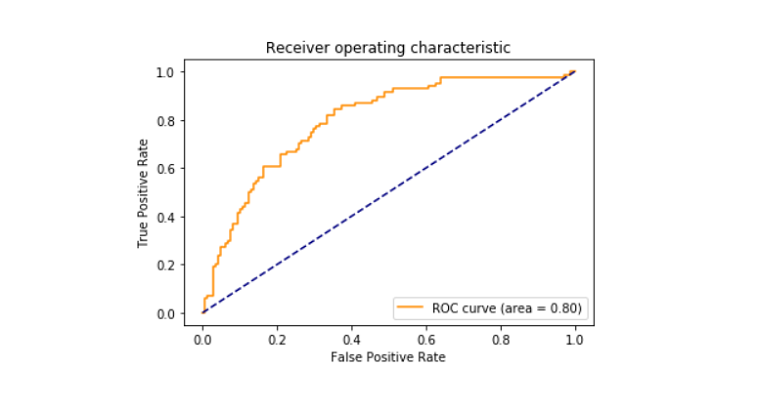
Roc_curve
O receiver operating characteristic curve também conhecido como roc_curve é um enredo que fala sobre a interpretação do potencial de um classificador binário do sistema. É plotada entre a taxa verdadeira positiva e a taxa falsa positiva em diferentes limiares. A área da curva ROC foi encontrada em 0,80.
para o ficheiro python e também para o conjunto de dados usado no problema acima, pode referir-se à ligação do Github aqui que contém ambos.,
Conclusion
In this blog, I have discussed Naive Bayes algorithms used for classification tasks in different contexts. Eu discuti Qual é o papel do teorema de Bayes no classificador de NB, diferentes características de NB, vantagens e desvantagens de NB, aplicação de NB, e na última eu tomei uma declaração de problema de Kaggle que é sobre classificar pacientes como diabéticos ou não.