luați în considerare un caz în care ați creat caracteristici, știți despre importanța caracteristicilor și trebuie să faceți un model de clasificare care urmează să fie prezentat într-o perioadă foarte scurtă de timp?
ce vei face? Aveți un volum foarte mare de puncte de date și foarte puține caracteristici în setul de date., În această situație, dacă ar fi trebuit să fac un astfel de model, aș fi folosit „naive Bayes”, care este considerat a fi un algoritm foarte rapid atunci când vine vorba de sarcini de clasificare.
în acest blog, încerc să explic cum funcționează algoritmul care poate fi utilizat în aceste tipuri de scenarii. Dacă doriți să știți ce este clasificarea și alți astfel de algoritmi vă puteți referi aici.Naive Bayes este un model de învățare automată care este utilizat pentru volume mari de date, chiar dacă lucrați cu date care au milioane de înregistrări de date, abordarea recomandată este Naive Bayes., Oferă rezultate foarte bune atunci când vine vorba de sarcini NLP, cum ar fi analiza sentimentală. Este un algoritm de clasificare rapid și necomplicat.pentru a înțelege clasificatorul naiv Bayes, trebuie să înțelegem teorema Bayes. Să discutăm mai întâi Teorema lui Bayes.
Teorema Bayes
este o teoremă care funcționează pe probabilitate condiționată. Probabilitatea condiționată este probabilitatea ca ceva să se întâmple, având în vedere că a avut loc deja altceva. Probabilitatea condiționată ne poate da probabilitatea unui eveniment folosind cunoștințele sale anterioare.,
probabilitate Condiționată:
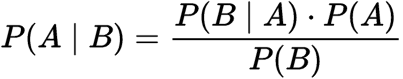
Probabilitate Condiționată
în cazul în Care,
P(A): probabilitatea ca ipoteza H fiind adevărat. Aceasta este cunoscută sub numele de probabilitatea anterioară.
P (B): probabilitatea dovezilor.
P (A / B): probabilitatea dovezilor date că ipoteza este adevărată.
P (B / A): Probabilitatea ipotezei având în vedere că dovezile sunt adevărate.
Naive Bayes clasificator
-
este un fel de clasificator care funcționează pe teorema Bayes.,Predicția probabilităților de membru se face pentru fiecare clasă, cum ar fi probabilitatea punctelor de date asociate unei anumite clase.
-
clasa cu probabilitate maximă este evaluată ca fiind cea mai potrivită clasă.
- acest lucru este, de asemenea, menționată ca Maxim a Posteriori (hartă). clasificatorii NB concluzionează că toate variabilele sau caracteristicile nu sunt legate între ele.
-
existența sau absența unei variabile nu afectează existența sau absența oricărei alte variabile.,
-
exemplu:
-
se poate observa că fructul este un măr dacă este roșu, rotund și cu diametrul de aproximativ 4″.în acest caz, de asemenea, chiar dacă toate caracteristicile sunt interdependente între ele, și NB clasificator va observa toate acestea contribuie în mod independent, la probabilitatea ca fructul este un măr. noi experimentăm cu ipoteza în seturi de date reale, având în vedere mai multe caracteristici. deci, calculul devine complex.
tipuri de algoritmi naivi Bayes
1., Gaussian naive Bayes: când valorile caracteristice sunt continue în natură, atunci se face o presupunere că valorile legate de fiecare clasă sunt dispersate în funcție de Gaussian, care este distribuția normală.
2. Bayes naivi multinomiali: Bayes naivi Multinomiali este favorizat să se utilizeze pe date distribuite multinomial. Este utilizat pe scară largă în clasificarea textului în NLP. Fiecare eveniment din clasificarea textului constituie prezența unui cuvânt într-un document.
3., Bernoulli naive Bayes: atunci când datele sunt distribuite în conformitate cu distribuțiile Bernoulli multivariate, se utilizează Bernoulli Naive Bayes. Asta înseamnă că există mai multe caracteristici, dar se presupune că fiecare conține o valoare binară. Deci, este nevoie de caracteristici care să fie evaluate binar.
avantajele și dezavantajele Bayes Naive
avantaje:
-
este un algoritm foarte extensibil, care este foarte rapid.poate fi folosit atât pentru binare, cât și pentru clasificarea multiclaselor.,
-
are, în principal, trei tipuri diferite de algoritmi care sunt GaussianNB, MultinomialNB, BernoulliNB.
-
este un algoritm celebru pentru clasificarea e-mail spam.acesta poate fi ușor instruit pe seturi de date mici și poate fi folosit și pentru volume mari de date.
dezavantaje:
-
principalul dezavantaj al NB este luarea în considerare a tuturor variabilelor independente care contribuie la probabilitate.,
aplicații ale algoritmilor naivi Bayes
-
predicție în timp Real: fiind un algoritm de învățare rapidă poate fi folosit și pentru a face predicții în timp real.
-
multiclass clasificare: acesta poate fi folosit pentru probleme de clasificare mai multe clase, de asemenea.
-
Clasificarea textului: deoarece a arătat rezultate bune în prezicerea clasificării cu mai multe clase, astfel încât are mai multe rate de succes în comparație cu toți ceilalți algoritmi. Ca rezultat, este utilizat în principal în analiza sentimentului & detectarea spamului.,
Hands-On declarație problemă
declarația problemă este de a clasifica pacienții ca diabetici sau non-diabetici. Setul de date poate fi descărcat de pe site-ul Kaggle care este „PIMA Indian DIABETES DATABASE”. Seturile de date au avut mai multe caracteristici predictor medicale diferite și un obiectiv care este „rezultatul”. Variabilele Predictor includ numărul de sarcini pe care pacientul le-a avut, IMC-ul, nivelul insulinei, vârsta și așa mai departe.,
de implementare a Codului de importul și divizarea datelor
PAȘI-
- Inițial, toate bibliotecile necesare sunt importate ca numpy, panda, tren-test_split, GaussianNB, valori.
- deoarece este un fișier de date fără antet, vom furniza numele coloanelor care au fost obținute din URL-ul de mai sus
- a creat o listă python de nume de coloane numite „nume”.
- variabile predictor inițializate și ținta care este X și Y, respectiv.
- transformat datele folosind StandardScaler.,
- împărțiți datele în seturi de instruire și testare.
- a creat un obiect pentru GaussianNB.
- a montat datele din model pentru a-l antrena.
- a făcut predicții pe setul de testare și l-a stocat într-o variabilă „predictor”.
pentru a face analiza datelor exploratorii din setul de date puteți căuta tehnicile.
Confuzie-matrice & model scorul de date de testare
- Importate accuracy_score și confusion_matrix de sklearn.metrics., Imprimat matricea de confuzie între prezis și real, care ne spune performanța reală a modelului.
- calculat model_score a datelor de testare pentru a ști cât de bun este modelul performante în generalizarea celor două clase care au ieșit să fie 74%.,
model_score = model.score(X_test, y_test)model_scoreEvaluarea model
Roc_score
- Importate asc, roc_curve din nou la sklearn.metrics.
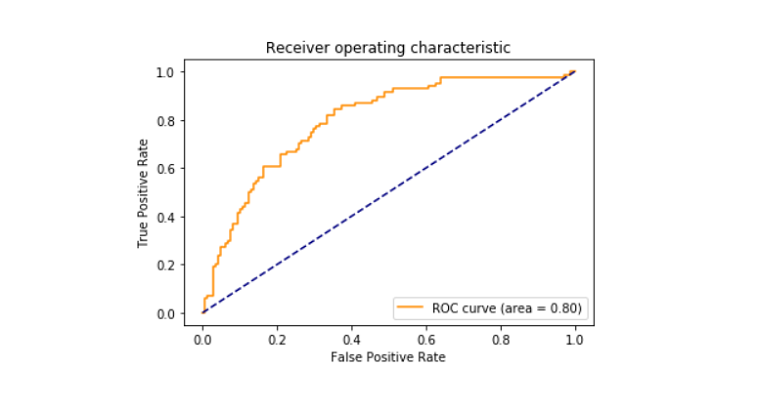
- Printed roc_auc scor între fals pozitiv și adevărat pozitiv, care a ieșit să fie 79%.
- matplotlib importate.biblioteca pyplot pentru a complot roc_curve.
- tipărit roc_curve.,
Roc_curve
receiver operating characteristic curve, de asemenea, cunoscut sub numele de roc_curve este un complot care spune despre potențialul de interpretare a unui clasificator binar sistem. Acesta este reprezentat grafic între rata pozitivă reală și rata fals pozitivă la praguri diferite. Zona curbei ROC sa dovedit a fi 0.80.
pentru fișierul python și, de asemenea, setul de date utilizat în problema de mai sus, puteți consulta linkul Github aici care conține ambele.,
concluzie
În acest blog, am discutat algoritmi Bayes Naive utilizate pentru sarcini de clasificare în diferite contexte. Am discutat care este rolul teoremei Bayes în clasificatorul NB, caracteristicile diferite ale NB, avantajele și dezavantajele NB, aplicarea NB, iar în ultima am luat o declarație de problemă de la Kaggle care se referă la clasificarea pacienților ca diabetici sau nu.
-