Tänk på ett fall där du har skapat funktioner, du vet om vikten av funktioner och du ska göra en klassificeringsmodell som ska presenteras på mycket kort tid?
vad ska du göra? Du har en mycket stor mängd datapunkter och mycket mindre få funktioner i din datauppsättning., I den situationen om jag var tvungen att göra en sådan modell skulle jag ha använt ”naiva Bayes”, som anses vara en riktigt snabb algoritm när det gäller klassificeringsuppgifter.
i den här bloggen försöker jag förklara hur algoritmen fungerar som kan användas i dessa typer av scenarier. Om du vill veta vad som är klassificering och andra sådana algoritmer kan du referera här.
Naive Bayes är en maskininlärningsmodell som används för stora datavolymer, även om du arbetar med data som har miljontals dataposter är den rekommenderade metoden naiva Bayes., Det ger mycket bra resultat när det gäller NLP uppgifter som sentimental analys. Det är en snabb och okomplicerad klassificeringsalgoritm.
för att förstå naiva Bayes klassificerare måste vi förstå Bayes teorem. Så låt oss först diskutera Bayes teorem.
Bayes sats
det är en sats som fungerar på villkorlig sannolikhet. Villkorlig sannolikhet är sannolikheten att något kommer att hända, med tanke på att något annat redan har inträffat. Den villkorliga sannolikheten kan ge oss sannolikheten för en händelse med dess förkunskaper.,
villkorlig sannolikhet:
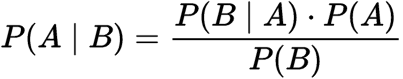
villkorlig sannolikhet
VAR,
P(A): sannolikheten för hypotesen H är sann. Detta är känt som den tidigare sannolikheten.
P(b): sannolikheten för bevisen.
P(A|B): sannolikheten för beviset med tanke på att hypotesen är sann.
P(B|A): sannolikheten för hypotesen med tanke på att bevisen är sanna.
naiv Bayes klassificerare
-
det är en typ av klassificerare som fungerar på Bayes teorem.,
-
förutsägelse av sannolikheter för medlemskap görs för varje klass, såsom sannolikheten för datapunkter associerade till en viss klass.
-
den klass som har maximal sannolikhet bedöms som den lämpligaste klassen.
- detta kallas även Maximum a Posteriori (karta).
-
OBS klassificerare drar slutsatsen att alla variabler eller funktioner inte är relaterade till varandra.
-
förekomsten eller frånvaron av en variabel påverkar inte förekomsten eller frånvaron av någon annan variabel.,
-
exempel:
-
frukt kan observeras vara ett äpple om det är rött, runt och ca 4″ i diameter.
-
i detta fall även om alla funktioner är inbördes samband med varandra, och NB klassificerare kommer att observera alla dessa oberoende bidrar till sannolikheten att frukten är ett äpple.
-
-
vi experimenterar med hypotesen i verkliga datauppsättningar, givet flera funktioner.
-
så blir beräkningen komplex.
typer av naiva Bayes algoritmer
1., Gaussisk naiv Bayes: när karakteristiska värden är kontinuerliga i naturen görs ett antagande att värdena kopplade till varje klass är dispergerade enligt Gaussisk som är Normal fördelning.
2. Multinomial Naive Bayes: Multinomial Naive Bayes är gynnad att använda på data som är multinomial distribuerad. Det används ofta i textklassificering i NLP. Varje händelse i textklassificering utgör närvaron av ett ord i ett dokument.
3., Bernoulli naiva Bayes: när data dispenseras enligt de multivariata Bernoullifördelningarna används Bernoulli naiva Bayes. Det betyder att det finns flera funktioner men var och en antas innehålla ett binärt värde. Så, det kräver funktioner för att vara binära värderas.
fördelar och nackdelar med naiva Bayes
fördelar:
-
det är en mycket utbyggbar algoritm som är mycket snabb.
-
den kan användas för både binärer och multiclass klassificering.,
-
det har främst tre olika typer av algoritmer som GaussianNB, MultinomialNB, BernoulliNB.
-
det är en känd algoritm för spam e-post klassificering.
-
det kan lätt utbildas på små datauppsättningar och kan användas för stora volymer av data också.
nackdelar:
-
den största nackdelen med NB överväger alla variabler oberoende som bidrar till sannolikheten.,
tillämpningar av naiva Bayes algoritmer
-
realtid förutsägelse: att vara en snabb inlärningsalgoritm kan användas för att göra förutsägelser i realtid samt.
-
MultiClass Klassificering: Den kan användas för flera klass klassificeringsproblem också.
-
Textklassificering: eftersom det har visat goda resultat när det gäller att förutsäga klassificering i flera klasser så att den har fler framgångsgrader jämfört med alla andra algoritmer. Som ett resultat används det majorly i sentimentanalys & spamdetektering.,
Hands-On Problem uttalande
problemet uttalande är att klassificera patienter som diabetiker eller icke-diabetiker. Datauppsättningen kan laddas ner från Kaggle webbplats som är ”Pima INDIAN DIABETES DATABASE”. Datauppsättningarna hade flera olika medicinska prediktorfunktioner och ett mål som är ”utfall”. Prediktorvariabler inkluderar antalet graviditeter som patienten har haft, deras BMI, insulinnivå, ålder och så vidare.,
kodimplementering för att importera och dela upp data
steg –
- inledningsvis importeras alla nödvändiga bibliotek som numpy, pandas, train-test_split, GaussianNB, metrics.
- eftersom det är en datafil utan rubrik kommer vi att tillhandahålla kolumnnamnen som har erhållits från ovanstående URL
- skapade en python-lista med kolumnnamn som heter ”namn”.
- initierade prediktorvariabler och målet som är X respektive Y.
- transformerade data med StandardScaler.,
- dela upp data i utbildnings-och testuppsättningar.
- skapade ett objekt för GaussianNB.
- monterade data i modellen för att träna den.
- gjorde förutsägelser på testuppsättningen och lagrade den i en ”prediktor” – variabel.
för att göra utforskande dataanalys av datauppsättningen kan du leta efter teknikerna.

förvirring-matris & testdata för modellresultat
- Importerad accuracy_score och confusion_matrix från sklearn.mått., Tryckt förvirringsmatrisen mellan förutsagd och faktisk som berättar modellens faktiska prestanda.
- beräknade modell_score för testdata för att veta hur bra modellen presterar för att generalisera de två klasserna som kom ut att vara 74%.,
model_score = model.score(X_test, y_test)model_score

utvärdering av modellen

roc_score
- importerat AUC, roc_curve igen från sklearn.mått.
- tryckt roc_auc-poäng mellan falskt positivt och Sant positivt som kom ut att vara 79%.
- Importerad matplotlib.pyplot bibliotek för att rita roc_curve.
- skrev ut roc_curve.,
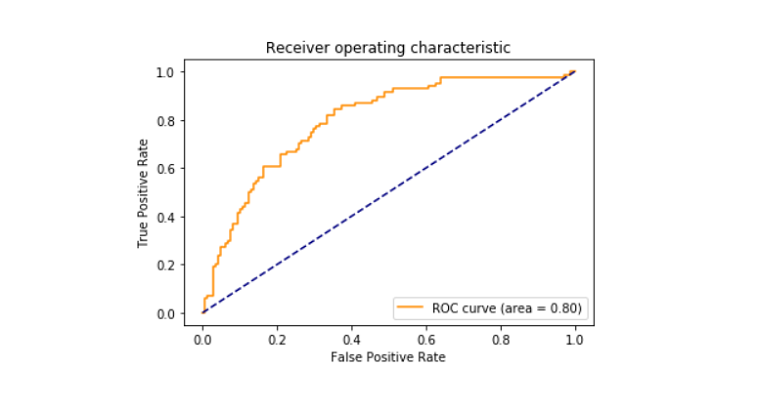
Roc_curve
mottagaren som arbetar karakteristisk kurva även känd som roc_curve är en tomt som berättar om tolkningspotentialen hos ett binärt klassificeringssystem. Det är ritat mellan den verkliga positiva hastigheten och den falska positiva hastigheten vid olika tröskelvärden. Roc-kurvan visade sig vara 0,80.
för python-filen och även den använda datauppsättningen i ovanstående problem kan du referera till GitHub-länken här som innehåller båda.,
slutsats
i den här bloggen har jag diskuterat naiva Bayes algoritmer som används för klassificeringsuppgifter i olika sammanhang. Jag har diskuterat vad som är rollen av Bayes teorem i NB klassificerare, olika egenskaper NB, fördelar och nackdelar med NB, tillämpning av NB, och i det sista har jag tagit ett problem uttalande från Kaggle som handlar om att klassificera patienter som diabetiker eller inte.