overvej en sag, hvor du har oprettet funktioner, ved du om vigtigheden af funktioner, og du skal lave en klassifikationsmodel, der skal præsenteres på meget kort tid?
Hvad vil du gøre? Du har en meget stor mængde datapunkter og meget mindre få funktioner i dit datasæt., I den situation, hvis jeg skulle lave en sådan model, ville jeg have brugt ‘Naive Bayes’, det anses for at være en rigtig hurtig algoritme, når det kommer til klassificeringsopgaver.
i denne blog forsøger jeg at forklare, hvordan algoritmen fungerer, der kan bruges i disse slags scenarier. Hvis du vil vide, hvad der er klassificering og andre sådanne algoritmer, kan du henvise her.Naive Bayes er en maskinlæringsmodel, der bruges til store datamængder, selvom du arbejder med data, der har millioner af dataposter, er den anbefalede tilgang naiv Bayes., Det giver meget gode resultater, når det kommer til NLP-opgaver såsom sentimental analyse. Det er en hurtig og ukompliceret klassifikation algoritme.
for at forstå den naive Bayes-klassifikator er vi nødt til at forstå Bayes-sætningen. Så lad os først diskutere Bayes-sætningen.
Bayes Theorem
det er en sætning, der virker på betinget sandsynlighed. Betinget sandsynlighed er sandsynligheden for, at noget vil ske, da der allerede er sket noget andet. Den betingede sandsynlighed kan give os sandsynligheden for en begivenhed ved hjælp af dens forudgående viden.,
Betinget sandsynlighed:
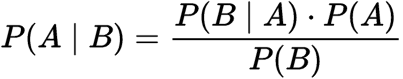
Betingede Sandsynlighed
Hvor
P(A): sandsynligheden for at hypotesen H er sandt. Dette er kendt som den forudgående Sandsynlighed.
P(b): sandsynligheden for beviset.
P(A / B): sandsynligheden for de beviser, der er givet, at hypotesen er sand.
P(b|a): sandsynligheden for hypotesen, da beviset er sandt.
naiv Bayes Classifier
-
det er en slags klassifikator, der virker på Bayes sætning.,
-
forudsigelse af medlemskab sandsynligheder er lavet for hver klasse, såsom sandsynligheden for datapunkter knyttet til en bestemt klasse.
-
den klasse, der har maksimal sandsynlighed, vurderes som den mest egnede klasse.
- dette kaldes også Ma .imum a Posteriori (kort).
-
NB-klassifikatorer konkluderer, at alle variabler eller funktioner ikke er relateret til hinanden.
-
eksistensen eller fraværet af en variabel påvirker ikke eksistensen eller fraværet af nogen anden variabel.,
-
eksempel:
-
frugt kan observeres at være et æble, hvis det er rødt, rundt og omkring 4″ i diameter.
-
i dette tilfælde også selvom alle funktionerne er indbyrdes forbundne, og NB classifier vil observere alle disse uafhængigt bidrage til sandsynligheden for, at frugten er et æble.
-
-
vi eksperimenterer med hypotesen i rigtige datasæt, givet flere funktioner.
-
så bliver beregningen kompleks.
typer af Naive Bayes-algoritmer
1., Gauss Naive Bayes: når karakteristiske værdier er kontinuerlige i naturen, antages det, at de værdier, der er knyttet til hver klasse, er spredt i henhold til Gauss, der er Normal fordeling.
2. Multinomial Naive Bayes: Multinomial Naive Bayes foretrækkes at bruge på data, der er multinomial distribueret. Det er meget udbredt i tekstklassificering i NLP. Hver begivenhed i tekstklassificering udgør tilstedeværelsen af et ord i et dokument.
3., Bernoulli Naive Bayes: når data udleveres i henhold til de multivariate Bernoulli-distributioner, bruges Bernoulli Naive Bayes. Det betyder, at der findes flere funktioner, men hver enkelt antages at indeholde en binær værdi. Så det kræver funktioner, der skal binært værdsættes.
fordele og ulemper ved Naive Bayes
fordele:
-
det er en meget udvidelig algoritme, der er meget hurtig.
-
det kan bruges til både binære filer samt multiclass klassificering.,
-
det har hovedsageligt tre forskellige typer algoritmer, der er GaussianNB, MultinomialNB, BernoulliNB.
-
det er en berømt algoritme til klassificering af spam-e-mail.
-
det kan nemt trænes på små datasæt og kan også bruges til store datamængder.
ulemper:
-
den største ulempe ved NB overvejer alle variabler uafhængige, der bidrager til sandsynligheden.,
anvendelser af Naive Bayes-algoritmer
-
Realtidsforudsigelse: at være en hurtig læringsalgoritme kan også bruges til at foretage forudsigelser i realtid.
-
klassificering af flere klasser: det kan også bruges til klassificering af flere klasser.
-
Tekstklassificering: da det har vist gode resultater med at forudsige klassificering i flere klasser, så har den flere succesrater sammenlignet med alle andre algoritmer. Som et resultat bruges det hovedsageligt i sentimentanalyse & spamdetektion.,
Hands-On Problem Statement
problemstillingen er at klassificere patienter som diabetiske eller ikke-diabetiske. Datasættet kan do .nloades fra Kaggle-websiteebstedet, der er ‘Pima INDIAN DIABETES DATABASE’. Datasættene havde flere forskellige medicinske forudsigelsesfunktioner og et mål, der er ‘resultat’. Forudsigelsesvariabler inkluderer antallet af graviditeter, patienten har haft, deres BMI, insulinniveau, alder og så videre.,
Koden gennemførelse af import og opdeling af data
TRIN-
- i første omgang, alle de nødvendige biblioteker er importeret som numpy, pandaer, tog-test_split, GaussianNB, målinger.
- da det er en datafil uden overskrift, leverer vi kolonnenavne, der er opnået fra ovenstående URL
- oprettet en python-liste over kolonnenavne kaldet “navne”.
- initialiserede forudsigelsesvariabler og målet, der er henholdsvis respectively og Y.
- transformerede dataene ved hjælp af StandardScaler.,
- Opdel dataene i Trænings-og testsæt.
- oprettet et objekt til GaussianNB.
- monteret dataene i modellen for at træne dem.
- lavede forudsigelser på testsættet og lagrede det i en ‘predictor’ – variabel.
for at udføre den sonderende dataanalyse af datasættet kan du kigge efter teknikkerne.

Forvirring-matrix & model score test data
- Importerede accuracy_score og confusion_matrix fra sklearn.effektivitetsmålinger., Trykt forvirringsmatri .en mellem forudsagt og faktisk, der fortæller os den faktiske ydelse af modellen.
- beregnet model_score af testdataene for at vide, hvor god modellen udfører ved generalisering af de to klasser, der kom ud til at være 74%.,
model_score = model.score(X_test, y_test)model_score

Evaluering af model

Roc_score
- Importerede auc, roc_curve igen fra sklearn.effektivitetsmålinger.
- trykt roc_auc score mellem falsk positiv og sand Positiv, der kom ud til at være 79%.
- importeret matplotlib.pyplot bibliotek for at plotte roc_curve.
- trykt roc_curve.,
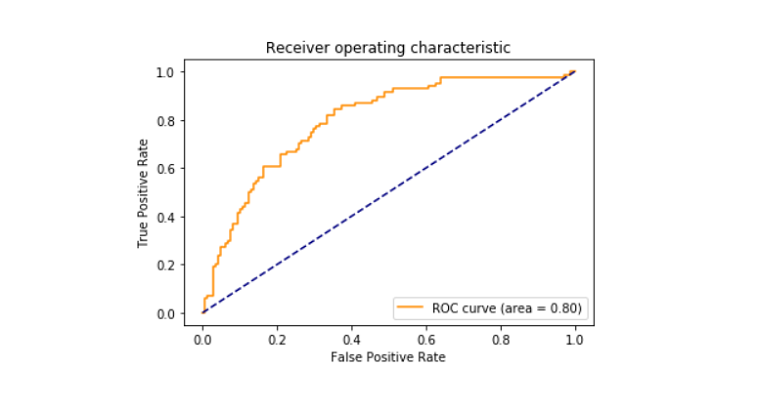
Roc_curve
receiver operating characteristic curve også kendt som roc_curve er et plot, der fortæller om fortolkningen potentiale af en binær klassificeringen system. Det er afbildet mellem den sande positive sats og den falske positive sats ved forskellige tærskler. ROC-kurveområdet viste sig at være 0,80.
for python-filen og også det anvendte datasæt i ovenstående problem kan du henvise til Github-linket her, der indeholder begge dele.,
konklusion
i denne blog har jeg diskuteret Naive Bayes-algoritmer, der bruges til klassificeringsopgaver i forskellige sammenhænge. Jeg har diskuteret hvilken rolle spiller Bayes teorem i NB Klassificeringen, forskellige karakteristika af NB, fordele og ulemper af NB, anvendelse af NB, og i det sidste har jeg taget et problem udtalelse fra Kaggle, der handler om klassificering af patienter som diabetikere eller ikke.