se generaron y utilizaron bibliotecas de Pam que contenían secuencias de ADN aleatorizadas inmediatamente aguas abajo de una secuencia de ADN complementaria al espaciador de un ARN guía para determinar empíricamente el reconocimiento de Pam de endonucleasas Cas9 Tipo II (Fig. 1)., Con la secuencia del objetivo del espaciador de ARN guía siendo fija, las bases aleatorias sirven como sustrato para la lectura directa de la especificidad de la endonucleasa PAM Cas9. Se introdujeron secuencias aleatorias en un vector de ADN plásmido en la región PAM de una secuencia objetivo de protospacer que demuestra una homología perfecta al espaciador de ARN guía T1 (CGCUAAAGAGGAAGAGGACA). Se generaron dos bibliotecas que aumentaron en tamaño y complejidad de cinco pares de bases aleatorias (1.024 combinaciones potenciales de PAM) a siete pares de bases aleatorias (16.384 combinaciones potenciales de PAM)., La aleatorización de la biblioteca de 5 pb se introdujo a través de la síntesis de un único oligonucleótido que contenía cinco residuos aleatorios. El oligonucleótido monocatenario fue convertido en una plantilla bicatenaria por PCR (archivo adicional 1: Figura S1A), clonado en el vector plásmido (archivo adicional 1: Figura S1B) y transformado en E. coli como se describe en la sección Métodos., Para asegurar una aleatoriedad óptima en la biblioteca PAM de 7 PB, el tamaño y la complejidad de la biblioteca se redujeron mediante la síntesis de cuatro oligonucleótidos que contenían cada uno seis residuos aleatorios más un séptimo residuo fijo que comprendía G, C, A O T, respectivamente. Cada uno de los cuatro oligonucleótidos se convirtió por separado en ADN de doble cadena, clonado en vector pTZ57R / T como se describe en la sección Métodos y transformado en E. coli como se describe para la biblioteca de 5 bp., Después de la transformación, el ADN plásmido se recuperó y se combinó de cada una de las cuatro bibliotecas PAM de 6 pb para generar una biblioteca PAM de 7 PB aleatoria que comprende 16,384 posibles combinaciones de PAM. Para ambas bibliotecas, la incorporación de aleatoriedad fue validada por secuenciación profunda; examinando la composición de nucleótidos en cada posición de la región PAM usando una matriz de frecuencia de posición (PFM) (sección de métodos y) (archivo adicional 1: Figura S2A y B)., La distribución y frecuencia de cada secuencia PAM en la biblioteca Pam aleatoria de 5 pb y 7 PB se muestran en el archivo adicional 1: Figuras S3 y S4, respectivamente.
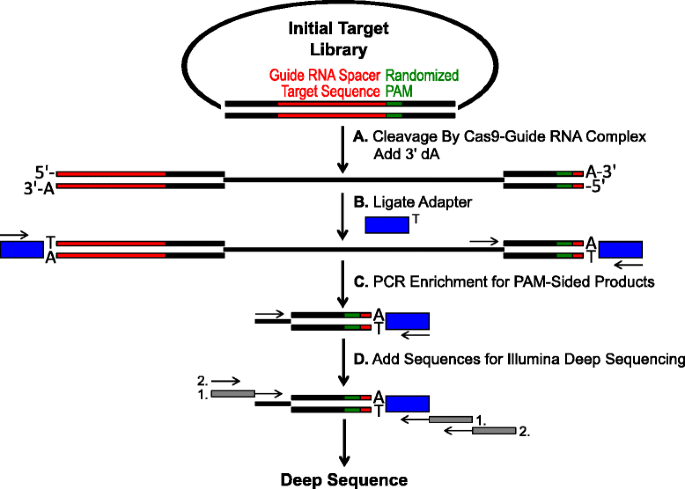
Fig. 1
esquema para la identificación de las preferencias de PAM por división Cas9 in vitro. una biblioteca inicial de plásmidos con Pam Aleatorio (caja verde) es escindida con complejo Cas9 y se agregan voladizos dA de 3′. los adaptadores b con voladizo de 3′ dT (caja azul) están unidos a ambos extremos del producto de hendidura., los cebadores c se utilizan para enriquecer los productos cortados por PCR., d después del enriquecimiento por PCR, los fragmentos de ADN se purifican y los anclajes y códigos de barras compatibles con Illumina se ‘siguen’ a través de dos rondas de PCR (cajas grises) e Illumina secuenciado en profundidad
análisis de las preferencias de Pam Cas9
Las bibliotecas Pam aleatorias descritas en la sección anterior se sometieron a digestión in vitro con diferentes concentraciones de proteína Cas9 recombinante precargado con ARN guía para evaluar las preferencias de la endonucleasa Cas9 PAM de manera dosis-dependiente., Después de la digestión con complejos de ribonucleoproteína de ARN guía Cas9 (RNP), las combinaciones de secuencias PAM de la biblioteca Pam aleatoria que soportaban la escisión fueron capturadas mediante la ligadura de adaptadores a los extremos libres de las moléculas de ADN plásmido escindidas por el complejo de ARN guía Cas9 (Fig. 1a y b). Para promover la ligadura eficiente y la captura de los extremos escindidos, el corte de ADN de doble cadena de extremo romo generado por las endonucleasas Cas9 se modificó para contener un voladizo de 3′ dA y los adaptadores se modificaron para contener un voladizo complementario de 3′ dT., Para generar cantidades suficientes de ADN para la secuenciación, los fragmentos de ADN que albergaban la secuencia PAM que soportaba la escisión fueron amplificados por PCR usando una imprimación en el adaptador y otra directamente adyacente a la región PAM (Fig. 1c). Las bibliotecas Pam Cas9 amplificadas por PCR resultantes se convirtieron en plantillas ampli-seq (Fig. 1d) y secuenciado profundo de una sola lectura desde el lado adaptador del amplicon., Para garantizar una cobertura adecuada, las bibliotecas Pam Cas9 se secuenciaron a una profundidad al menos cinco veces mayor que la diversidad en la biblioteca Pam aleatoria inicial (5,120 y 81,920 lecturas para las bibliotecas Pam aleatorias de 5 y 7 PB, respectivamente). Las secuencias PAM se identificaron a partir de los datos de secuencia resultantes seleccionando solo aquellas lecturas que contenían una coincidencia perfecta de secuencia de 12 nt que flanqueaban cualquiera de los lados de la secuencia PAM de 5 o 7 nt (dependiendo de la biblioteca Pam aleatoria utilizada); capturando solo aquellas secuencias Pam resultantes del reconocimiento y escisión del Sitio objetivo de ARN guía Cas9 perfecto., Para compensar el sesgo inherente en las bibliotecas Pam aleatorias iniciales, la frecuencia de cada secuencia PAM se normalizó a su frecuencia en la biblioteca inicial. Dado que el ensayo descrito aquí captura directamente las secuencias Pam dividibles de Cas9, se utilizó un modelado probabilístico para calcular el consenso de PAM para cada proteína Cas9. Esto se logró mediante la evaluación de la probabilidad de encontrar cada nucleótido (G, C, A O T) en cada posición de la secuencia PAM de forma independiente utilizando una matriz de frecuencia de posición (PFM) (sección de métodos y )., Las probabilidades resultantes se visualizaron como un WebLogo .
para examinar la propensión a falsos positivos en el ensayo, se omitió la adición de complejos Cas9 RNP en la etapa de digestión (Fig. 1a)y el ensayo se realizó mediante la etapa de enriquecimiento por PCR (Fig. 1c). Como se muestra en el archivo adicional 1: Figura S5A, no se detectaron productos de amplificación en ausencia de complejos de ARN guía Cas9. Por lo tanto, lo que indica que la incidencia de falsos positivos es baja y no contribuye significativamente a los resultados del ensayo.,
preferencias PAM de Streptococcus pyogenes y Streptococcus thermophilus (sistemas CRISPR3 y CRISPR1) proteínas Cas9
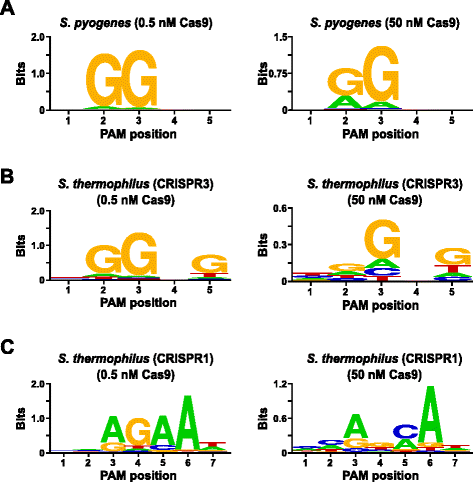
para validar el ensayo, se examinaron las preferencias PAM de Streptococcus pyogenes (Spy) y Streptococcus thermophilus CRISPR3 (Sth3) proteínas Cas9, cuyos requerimientos de secuencia PAM han sido reportados previamente. Se realizaron digestiones In vitro con 1 µg (5,6 nM) de la biblioteca Pam aleatorizada de 5 bp a dos concentraciones, 0,5 y 50 nM, de complejos RNP de proteína Spy o Sth3 Cas9 preensamblados, arncr y ARNr tracr durante 1 h en un volumen de reacción de 100 µL., Con base en su frecuencia en la biblioteca Pam aleatoria de 5 bp, las secuencias Pam Spy y Sth3 Cas9 (NGG y NGGNG, respectivamente) se encontraron en concentraciones finales de 0.40 nM y 0.11 nM en la digestión, respectivamente. Los miembros de la biblioteca Pam aleatoria que contenía secuencias PAM que apoyaban la escisión fueron capturados e identificados como se describe en la sección anterior. Como control negativo, la biblioteca Pam aleatoria inicial sin depurar fue sujeta a secuenciación y análisis PFM junto con aquellas bibliotecas expuestas a complejos RNP Cas9., Como se muestra en el archivo adicional 1: Figura S5B y C, no existen preferencias de secuencia en ausencia de digestión compleja Cas9 RNP como evidente por una distribución casi perfecta de cada nucleótido en cada posición de la PAM en la tabla PFM y la falta de contenido informativo en el WebLogo para el control. Esto está en stark constrast con la Fig. 2a y b que ilustran la composición de las secuencias derivadas de bibliotecas digeridas con complejos Spy y Sth3 Cas9 RNP. Examen de los WebLogos derivados de PFM (Fig., 2a y b) también revelan la presencia de las preferencias canónicas PAM para las proteínas Spy y Sth3 Cas9, NGG y NGGNG , respectivamente. Aunque las preferencias de PAM reportadas para las proteínas Spy y Sth3 Cas9 se observan tanto en los digests de 0.5 nM como en los de 50 nM, hay un ensanchamiento general en la especificidad bajo las condiciones de digest de 50 nM. Esto es más evidente en la posición 2 para la proteína Spy Cas9, donde la frecuencia de un residuo A no canónico aumenta dramáticamente (Fig. 2a)., For Sth3, all PAM positions exhibit a marked decrease in specificity as a result of increasing the RNP complex concentration (Fig. 2b).
Fig. 2
PAM preferences for S. pyogenes (a), S. thermophilus CRISPR3 (b), and S. thermophilus CRISPR1 (c) Cas9 proteins., La frecuencia de nucleótidos en cada posición PAM se calculó de forma independiente utilizando una matriz de frecuencia de posición (PFM) y se trazó como un WebLogo
se realizó una validación adicional del ensayo examinando las preferencias PAM para la proteína Streptococcus thermophilus CRISPR1 (Sth1) Cas9 cuya especificidad PAM se ha reportado que se extiende a 7 PB . Utilizando como plantilla 1 µg (5,6 nM) de la biblioteca Pam aleatoria de 7 PB, se realizaron digestiones de ARN guía Sth1 Cas9 en dos concentraciones, 0,5 nM y 50 nM, del complejo RNP como se describió anteriormente., Como controles, los complejos Spy y Sth3 Cas9 RNP también se utilizaron para digerir la biblioteca Pam aleatoria de 7 PB, pero solo a una concentración única de complejos RNP de 0,5 nM. Sobre la base de la frecuencia en la biblioteca Pam aleatorizada de 7 PB, las secuencias Pam reportadas previamente para Sth1 (NNAGAAW), Spy (NGG) y Sth3 (NGGNG) estaban en concentraciones finales de 0.01 nM, 0.22 nM y 0.05 nM, respectivamente., Como se muestra en el archivo adicional 1: Figura S6A y B, las preferencias de PAM para las proteínas Spy y Sth3 Cas9 generadas utilizando la biblioteca de 7 bp fueron casi idénticas a las producidas con la biblioteca de 5 bp que proporciona una fuerte evidencia de la reproducibilidad del ensayo. Las preferencias de PAM para la proteína Sth1 Cas9 también coincidieron estrechamente con las reportadas anteriormente , NNAGAAW, a la concentración del complejo de ARN guía Cas9 de 0.5 nM (Fig. 2c)., Similar a las proteínas Spy y Sth3 Cas9, Sth1 Cas9 fue capaz de escindir un conjunto más diverso de secuencias PAM en las reacciones que contienen una mayor concentración de Complejo de ARN guía Cas9 (50 nM), la más llamativa fue la marcada pérdida del requisito de residuo G en la posición 4 y la preferencia casi igual por una C y una bp en la posición 5 (Fig. 2c). Esto resultó en un consenso de PAM diferente al obtenido en concentraciones más bajas.,
para examinar si la especificidad PAM es independiente del tipo de ARN guía, también se examinaron las preferencias PAM de crrna duplexado:tracrRNA o sgRNA , Spy, Sth3 y Sth1 Cas9 utilizando un complejo binario Cas9 y sgrna RNP. La digestión se llevó a cabo a una sola concentración compleja de RNP de 0,5 nM y el análisis de preferencia PAM se realizó como se describió anteriormente. Como se muestra en el archivo adicional 1: Figura S7A, B y C, las preferencias de PAM fueron casi idénticas independientemente del tipo de ARN guía utilizado; ya sea un arncr:tracrRNA dúplex o sgRNA., Además, para confirmar que la especificidad de PAM no está muy influenciada por la composición del ADN objetivo o la secuencia del espaciador, la secuencia en el lado opuesto de la biblioteca aleatoria de 5 o 7 PB fue dirigida para la escisión con un espaciador diferente; T2-5 (UCUAGAUAGAUUACGAAUUC) para la biblioteca de 5 pb o T2-7 (CCGGCGACGUUGGGUCAACU) para la biblioteca de 7 PB. Las proteínas Spy y Sth3 Cas9 precargadas con sgRNAs dirigidas a la secuencia T2 se utilizaron para interrogar la biblioteca Pam aleatoria de 5 pb, mientras que los complejos Sgrna Sth1 Cas9-T2 se utilizaron para digerir la biblioteca Pam aleatoria de 7 PB., Las preferencias de PAM se evaluaron como se describió anteriormente. Las preferencias de PAM para las 3 proteínas Cas9 fueron casi idénticas independientemente del espaciador y la secuencia de ADN objetivo (archivo adicional 1: Figura S8A, B y C).
identificación de las preferencias de sgRNA y PAM para la proteína Brevibacillus Laterosporus Cas9
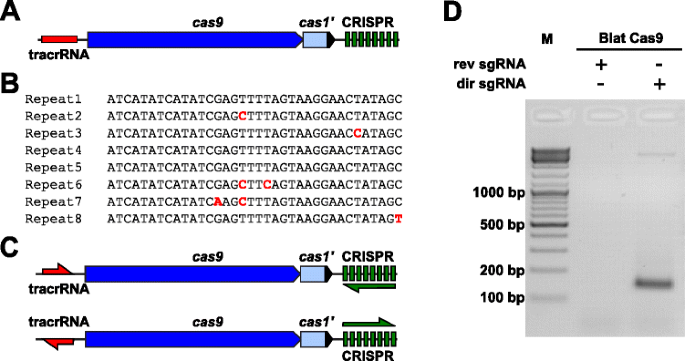
para examinar empíricamente las preferencias de PAM para una proteína Cas9 cuya PAM no estaba definida, se identificó un locus CRISPR-Cas tipo II-C no caracterizado de la cepa Brevibacillus laterosporus ssp360d4 (Blat) mediante la búsqueda de ortólogos Cas9 en las bases de datos internas de DuPont Pioneer., El locus (aproximadamente 4.5 kb) contenía un gen cas9 capaz de codificar un polipéptido 1,092, una matriz CRISPR que comprende siete unidades de espaciador de repetición justo aguas abajo del gen cas9 y una región de codificación tracrRNA ubicada aguas arriba del gen cas9 con homología parcial a las repeticiones de la matriz CRISPR (Fig. 3a). La repetición y la longitud del espaciador (36 y 30 pb, en consecuencia) es similar a otros sistemas CRISPR-Cas tipo II con cinco de las ocho repeticiones que contienen 1 o 2 mutaciones PB (Fig. 3B Y archivo adicional 1: Figura S9)., Otros genes típicamente encontrados en un locus CRISPR-Cas tipo II estaban truncados (cas1) o faltaban (Fig. 3a).
Fig. 3
identificación de elementos CRISPR-Cas tipo II en el sistema CRISPR-Cas Brevibacillus laterosporus SSP360D4. a ilustración de la región genómica del ADN del sistema CRISPR-Cas tipo II de Brevibacillus laterosporus SSP360D4. B comparación de secuencias de repetición de matriz CRISPR tipo II identificadas en Brevibacillus laterosporus SSP360D4., C los escenarios transcripcionales de tracrRNA y matriz CRISPR’ directos ‘e’ inversos ‘ para el sistema CRISPR-Cas tipo II de Brevibacillus laterosporus SSP360D4. d un gel de agarosa con productos de reacción, lo que indica que solo el sgRNA ‘directo’ (dir sgRNA), pero no el sgrna ‘inverso’ (rev sgrna) admite la división de la biblioteca de plásmidos en combinación con la endonucleasa Cas9 originaria de Brevibacillus laterosporus ssp360d4
el requisito de ARN guía para la proteína Cas9 de blat se determinó generando dos variantes de sgrna., Estas variantes se generaron para tener en cuenta tanto los posibles escenarios de expresión de sentido o anti-sentido del array tracrRNA y CRISPR (Fig. 3c) y utilizado para sondear qué escenario de expresión soportaba la actividad de escisión de Blat Cas9 en la biblioteca Pam aleatoria. Los ARN de guía única se diseñaron identificando primero los límites de las moléculas de tracrRNA putativas mediante el análisis de regiones que eran parcialmente complementarias al terminal 22 nt 5′ de la repetición (anti-repetición)., A continuación, para determinar el extremo 3′ del tracrRNA, se utilizaron posibles estructuras secundarias y terminadores para predecir la región de terminación en el fragmento aguas abajo. Esto se logró mediante la detección de la presencia de secuencias de terminación Rho independientes en el ADN que rodea la anti-repetición similar a la descrita en Karvelis et al. , convirtiendo el ADN circundante en secuencia de ARN y examinando las estructuras resultantes usando UNAfold ., Los sgRNAs resultantes fueron diseñados para contener una señal de reconocimiento de inicio de transcripción de polimerasa T7 en el extremo 5′ seguido de una secuencia de reconocimiento objetivo de 20 nt, 16 nt de repetición de crRNA, 4 NT de bucle de horquilla auto-plegable y una secuencia anti-repetición complementaria a la región de repetición del crRNA seguida por la parte restante de 3′ del putativo tracrRNA. La variante sgRNA que contiene un tracrRNA putativo transcrito en la misma dirección que el gen cas9 (Fig. 3c) se denomina sgRNA ‘directo’, mientras que el sgrna que contiene el tracrRNA transcribe en la dirección opuesta un sgRNA’ inverso’., Cincuenta nM de Blat Cas9 sgrna RNP complex, precargado con los sgRNAs’ directo ‘o’ inverso’, respectivamente, fueron incubados con 1 µg (5.6 nM) de la biblioteca Pam aleatoria de 7 PB. Después de la digestión de la biblioteca y la adición de voladizos de 3 ‘ dA, los adaptadores se ligaron y los productos de escisión se amplificaron por PCR (Fig. 1). El análisis de los productos de reacción por electroforesis en gel de agarosa reveló que el sgRNA ‘directo’, pero no el sgRNA’ inverso ‘ soportaba la escisión de la biblioteca de plásmidos (Fig. 3d). La secuencia y la estructura secundaria predicha del sgRNA ‘DIRECTO’ se muestran en el archivo adicional 1: Figura S10.,
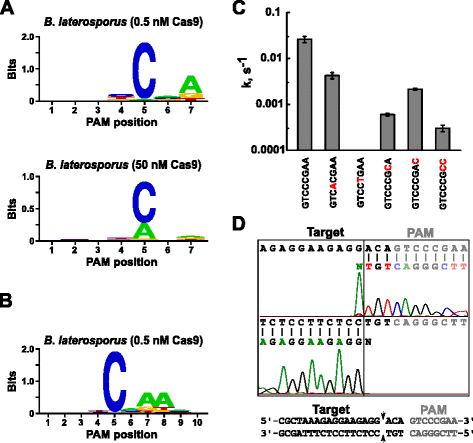
después de determinar el ARN guía apropiado para Blat Cas9, la identificación de PAM se realizó de manera similar a la descrita anteriormente para las proteínas Spy, Sth3 y Sth1 Cas9 contra la biblioteca Pam aleatorizada de 7 PB con dos concentraciones, 0,5 y 50 nM, del complejo sgrna RNP ‘directo’ de Blat Cas9 preensamblado. Como se muestra en la Fig. 4A, el consenso PFM WebLogo PAM para la proteína Blat Cas9 bajo las condiciones de digestión de 0.5 nM fue nnnncnd (N = G, C, A, O T; D = A, G, O T) con una fuerte preferencia por una C En la posición 5 de la secuencia PAM., Se observó una preferencia moderada por una A en la posición 7 y también se observaron ligeras preferencias por una C O T en la posición 4 y G, C o A Sobre T en la posición 6 al examinar de cerca la tabla de PFM (archivo adicional 1: Figura S11). De manera similar a las proteínas Spy, Sth3 y Sth1 Cas9, la especificidad PAM se amplía a medida que aumenta la concentración del complejo Cas9-sgRNA. Esto es más evidente en la posición 5, donde una mayor proporción de secuencias PAM que contienen un residuo a apoyan la escisión a 50 nM en comparación con las condiciones de digestión de 0,5 nM.
Fig., 4
preferencias PAM y posiciones de escisión de la enzima Brevibacillus laterosporus Ssp360d4 (Blat) Cas9. Blat Cas9 Pam preferencias cuando 1 µg de ADN biblioteca fue escindido con 0.5 nM o 50 nM Cas9-sgRNA complejo (a), extendido a la posición 10 mediante el cambio de la diana protospacer en 3 PB (b). La frecuencia de nucleótidos en cada posición PAM se calculó de forma independiente utilizando una matriz de frecuencia de posición (PFM) y se trazó como un WebLogo ., C tasas de escisión de sustratos de ADN plásmido superenrollado que contienen mutaciones (mostradas en rojo) en la secuencia PAM de GTCCCGAA. Todos los puntos de datos son valores medios de ≥3 experimentos independientes. Las barras de Error se dan como secuenciación de escorrentía S. D. d desde las direcciones sentido y anti-sentido del ADN plásmido escindido con Blat Cas9
ya que Blat Cas9 puede aceptar cualquier base en las tres primeras posiciones de su secuencia PAM (Fig. 4a), el espaciador T1 fue desplazado por tres nucleótidos en la dirección 5′ para permitir que la identificación PAM se extendiera de 7 a 10 PB., El espaciador T1 desplazado, T1-3 (Aaacgcuaaagaggaagaggg), se incorporó al sgRNA ‘directo’ de Blat y la identificación de PAM se realizó como se describió anteriormente para las proteínas Spy, Sth3, Sth1 y Blat Cas9. El análisis de preferencias de PAM reveló que la especificidad de Pam para Blat Cas9 puede extenderse a la posición 8 donde hay una preferencia moderada por una A adicional (Fig. 4b).
la especificidad de PAM para Blat Cas9 se confirmó mediante la generación de plásmidos que contienen mutaciones en los residuos más conservados de la PAM (Fig. 4c)., El reemplazo del nucleótido C En la posición 5 abolió la escisión del ADN del plásmido confirmando su papel clave en el reconocimiento de Pam de Cas9 Blat. El reemplazo de nucleótidos A en las posiciones 7 y 8 redujo significativamente (43× y 12×, respectivamente) la tasa de escisión del plásmido superenrollado, lo que también indica la importancia de estos nucleótidos en el reconocimiento de Blat Cas9 PAM.,
para identificar las posiciones de escisión del ADN objetivo para la proteína Blat Cas9, se generó un plásmido que contiene una región de 20 PB que coincide con el espaciador T1 seguido de una secuencia PAM, GTCCCGAA, que cae dentro del consenso PAM para Blat Cas9, NNNNCNDD, y se digirió con el complejo ribonucleoproteico de ARN guía de Blat Cas9. La secuenciación directa de ADN se utilizó para determinar los extremos de la molécula de ADN lineal generada por el complejo RNP Blat Cas9. Los resultados de la secuencia confirmaron que la escisión del ADN plásmido ocurrió en el protospacer 3 nt 5′ de la secuencia PAM (Fig., 4D) similar a la observada para las proteínas Spy, Sth3 y Sth1 Cas9 .
en la edición del genoma de planta utilizando Blat Cas9 y sgRNA
tras elucidar las preferencias de Sgrna y PAM para Blat Cas9, se generaron casetes de expresión de Cas9 y sgRNA optimizados para maíz para las pruebas de planta, como se describió anteriormente para el gen S. pyogenes cas9 y sgRNA . Brevemente, el gen blat cas9 fue optimizado con codón de maíz y se insertó el intrón 2 del gen St-LSI de papa para interrumpir la expresión en E. coli y facilitar el empalme óptimo en planta (archivo adicional 1: Figura S12)., La localización Nuclear de la proteína Blat Cas9 en células de maíz fue facilitada por la adición de señales de ubicaciones nucleares amino y carboxilo-terminal, SV40 (MAPKKKRKV) y Agrobacterium tumefaciens VirD2 (KRPRDRHDGELGGRKRAR), respectivamente (archivo adicional 1: Figura S12). El gen blat cas9 se expresó constitutivamente en las células vegetales mediante la vinculación de la cas9 optimizada a un promotor de ubiquitina de maíz y un terminador de pinII en un vector de ADN plásmido., Para conferir una expresión eficiente de sgRNA en células de maíz, se aisló un promotor y terminador de la polimerasa III de maíz U6 (TTTTTTTT) y se fusionó con los extremos 5′ y 3′ de una secuencia modificada de ADN codificante de Sgrna Blat, respectivamente (archivo adicional 1: Figura S13). El sgRNA blat modificado contenía dos modificaciones del utilizado en los estudios in vitro; una alteración de T A G en la posición 99 y una modificación de T A C En la posición 157 del sgRNA (archivo adicional 1: Figura S13). Los cambios fueron introducidos para eliminar potenciales señales prematuras de terminación de la polimerasa III U6 en el sgRNA Blat., Las alteraciones se introdujeron para tener un impacto mínimo en la estructura secundaria del sgRNA en comparación con la versión utilizada en los estudios in vitro (datos no mostrados).
para comparar con precisión la eficiencia mutacional resultante de la reparación imperfecta de unión final no homóloga (NHEJ) de roturas de doble hebra de ADN (DSBs) resultantes de la escisión de Spy y Blat Cas9, se seleccionaron sitios de blanco genómico idénticos a protospacer mediante la identificación de objetivos con PAMs compatibles con Spy y Blat Cas9, NGGNCNDD., Se seleccionaron secuencias de espaciador idénticas para Blat y Spy Cas9 capturando la secuencia de 18 a 21 nt inmediatamente aguas arriba del PAM. Para asegurar la expresión óptima de la polimerasa III U6 y no introducir un desajuste dentro del espaciador sgRNA, se seleccionaron todas las secuencias objetivo para terminar naturalmente en una G en su final de 5′. Se identificaron y seleccionaron objetivos en los exones 1 y 4 del gen de fertilidad del maíz Ms45 y en una región aguas arriba del gen de maíz liguleless-1.,
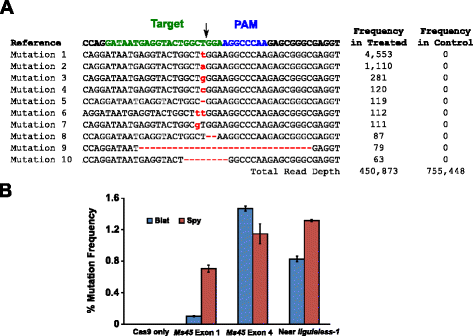
la actividad mutacional de Blat Cas9 en maíz se examinó mediante la transformación biológica de embriones de maíz inmaduros (IME) de 10 días de edad con vectores de ADN que contienen genes cas9 y sgrna. Blat y el equivalente Spy Cas9 y sgrna vectores de expresión fueron introducidos de forma independiente en maíz Hi-Tipo II IMEs por transformación de pistola de partículas similar a la descrita en . Dado que la transformación del cañón de partículas puede ser muy variable, un casete de expresión de ADN de marcador visual, Ds-Red, también se entregó conjuntamente con los vectores de expresión Cas9 y sgRNA para ayudar en la selección de IMEs uniformemente transformados., En total, se realizaron tres réplicas de transformación en 60-90 IMEs y 20-30 de los IMEs más uniformemente transformados de cada réplica se cosecharon 3 días después de la transformación. Se extrajo ADN genómico total y la región que rodea el sitio Objetivo se amplificó mediante PCR y amplicones secuenciados a una profundidad de lectura superior a 300.000. Las lecturas resultantes se examinaron para la presencia de mutaciones en el sitio esperado de escisión en comparación con los experimentos de control donde el casete de expresión de ADN sgRNA se omitió de la transformación. Como se muestra en la Fig., 5A, se observaron mutaciones en el sitio esperado de escisión para Blat Cas9 con los tipos más prevalentes de mutaciones siendo inserciones o deleciones de un solo par de bases. También se observaron patrones de reparación similares para la proteína Spy Cas9 (archivo adicional 1: Figura S14 y ). La actividad mutacional para Blat Cas9 fue robusta en dos de los tres sitios probados y superó la del Spy Cas9 en el Sitio objetivo del exón 4 Ms45 en aproximadamente un 30% (Fig. 5b).
Fig., 5
Brevibacillus Laterosporus Cas9 promueve mutaciones NHEJ en maíz. a Top 10 tipos más prevalentes de mutaciones nhej detectadas con Blat Cas9 en el exón 4 del gen Ms45. Una flecha negra indica el sitio esperado de escisión; las mutaciones se resaltan en rojo; la fuente en minúsculas indica una inserción; ‘-‘ indica una eliminación. B Comparison of Spy and Blat Cas9 nhej mutation frequencies at three protospacer identical target sites in maize. Las mutaciones de NHEJ se detectaron mediante secuenciación profunda 3 días después de la transformación., Las barras de Error representan SEM, n = 3 transformaciones de pistola de partículas. Cas9 solo es el control negativo y representa la frecuencia de fondo promedio (en los tres sitios objetivo) de las mutaciones resultantes de la amplificación y secuenciación de PCR