considere un caso en el que ha creado características, conoce la importancia de las características y se supone que debe hacer un modelo de clasificación que se presentará en un período de tiempo muy corto?
¿Qué harás? Tiene un volumen muy grande de puntos de datos y muy pocas características en su conjunto de datos., En esa situación, si tuviera que hacer un modelo de este tipo, habría utilizado ‘Naive Bayes’, que se considera un algoritmo realmente rápido cuando se trata de tareas de clasificación.
en este blog, estoy tratando de explicar cómo funciona el algoritmo que se puede utilizar en este tipo de escenarios. Si desea saber qué es la clasificación y otros algoritmos similares, puede consultar aquí.
Naive Bayes es un modelo de aprendizaje automático que se utiliza para grandes volúmenes de datos, incluso si está trabajando con datos que tienen millones de registros de datos, el enfoque recomendado es Naive Bayes., Da muy buenos resultados cuando se trata de tareas de PNL como el análisis sentimental. Es un algoritmo de clasificación rápido y sin complicaciones.
para entender el clasificador de Bayes ingenuo necesitamos entender el teorema de Bayes. Así que vamos a discutir primero el Teorema de Bayes.
Teorema de Bayes
es un teorema que funciona sobre la probabilidad condicional. La probabilidad condicional es la probabilidad de que algo suceda, dado que algo más ya ha ocurrido. La probabilidad condicional puede darnos la probabilidad de un evento usando su conocimiento previo.,
probabilidad Condicional:
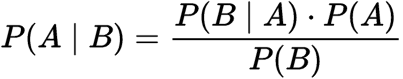
Probabilidad Condicional
Donde
P(a): La probabilidad de la hipótesis H de ser cierto. Esto se conoce como la probabilidad previa.
P(B): la probabilidad de La evidencia.
P (A / B): la probabilidad de la evidencia dada que la hipótesis es verdadera.
P(B|A): la probabilidad de La hipótesis, dado que la evidencia es cierto.
Naive Bayes Classifier
-
Es un tipo de clasificador que funciona en el teorema de Bayes.,
-
La Predicción de probabilidades de pertenencia se hace para cada clase, como la probabilidad de puntos de datos asociados a una clase en particular.
-
la clase que tiene máxima probabilidad se valora como la clase más adecuada.
- esto también se conoce como máximo a Posteriori (MAP).
-
los clasificadores NB concluyen que todas las variables o características no están relacionadas entre sí.
-
La Existencia o ausencia de una variable no afecta la existencia o ausencia de cualquier otra variable.,
-
ejemplo:
-
Se puede observar que la fruta es una manzana si es roja, redonda y de aproximadamente 4″ de diámetro.
-
en este caso también incluso si todas las características están interrelacionadas entre sí, y el clasificador NB observará todas estas independientemente contribuyendo a la probabilidad de que la fruta sea una manzana.
-
-
experimentamos con la hipótesis en conjuntos de datos reales, dadas múltiples características.
-
entonces, la computación se vuelve compleja.
tipos de Algoritmos Bayes ingenuos
1., Bayes Naïve gaussiano: cuando los valores característicos son de naturaleza continua, entonces se asume que los valores vinculados con cada clase se dispersan de acuerdo con gaussiano que es la distribución Normal.
2. Bayes naïve Multinomial: Bayes naïve Multinomial es favorecido para usar en datos que son multinomiales distribuidos. Es ampliamente utilizado en la clasificación de texto en PNL. Cada evento en la clasificación del texto constituye la presencia de una palabra en un documento.
3., Bernoulli Naïve Bayes: cuando los datos se dispensan de acuerdo con las distribuciones multivariantes de Bernoulli, se utiliza Bernoulli naïve Bayes. Eso significa que existen múltiples características, pero se supone que cada una contiene un valor binario. Por lo tanto, requiere que las características sean de valor binario.
ventajas y desventajas de Naive Bayes
ventajas:
-
es un algoritmo altamente extensible que es muy rápido.
-
se puede utilizar tanto para binarios como para clasificación multiclase.,
-
tiene principalmente tres tipos diferentes de algoritmos que son GaussianNB, MultinomialNB, BernoulliNB.
-
es un famoso algoritmo para la clasificación de correo electrónico spam.
-
se puede entrenar fácilmente en conjuntos de datos pequeños y también se puede usar para grandes volúmenes de datos.
Desventajas:
-
La principal desventaja de las NB es considerar todas las variables independientes que contribuye a la probabilidad.,
aplicaciones de Algoritmos Bayes ingenuos
-
predicción en tiempo Real: al ser un algoritmo de aprendizaje rápido, También se puede usar para hacer predicciones en tiempo real.
-
Clasificación multiclase: también se puede usar para problemas de clasificación multiclase.
-
clasificación de texto: ya que ha mostrado buenos resultados en la predicción de la clasificación multiclase, tiene más tasas de éxito en comparación con todos los demás algoritmos. Como resultado, se utiliza principalmente en el análisis de sentimiento & detección de spam.,
Hands-On Problem Statement
la declaración del problema es clasificar a los pacientes como diabéticos o no diabéticos. El conjunto de datos se puede descargar del Sitio Web de Kaggle que es ‘Pima INDIAN DIABETES DATABASE’. Los conjuntos de datos tenían varias características predictoras médicas diferentes y un objetivo que es «resultado». Las variables predictoras incluyen el número de embarazos que ha tenido la paciente, su IMC, nivel de insulina, edad, etc.,
implementación de código de importación y división de los datos
pasos –
- inicialmente, se importan todas las bibliotecas necesarias como numpy, pandas, train-test_split, GaussianNB, metrics.
- dado que es un archivo de datos sin encabezado, proporcionaremos los nombres de columna que se han obtenido de la URL anterior
- creado una lista de python de nombres de columna llamada «nombres».
- variables predictoras inicializadas y el objetivo que es X e Y Respectivamente.
- transformó los datos usando StandardScaler.,
- divida los datos en conjuntos de entrenamiento y pruebas.
- creó un objeto para GaussianNB.
- ajustó los datos en el modelo para entrenarlo.
- realizó predicciones en el conjunto de pruebas y las almacenó en una variable’ predictor’.
para hacer el análisis exploratorio de datos del conjunto de datos puede buscar las técnicas.

Confusion-matrix & model score test data
- Imported accuracy_score and confusion_matrix de sklearn.métricas., Imprimió la matriz de confusión entre predicho y real que nos dice el rendimiento real del modelo.
- calculó el model_score de los datos de prueba para saber qué tan bueno es el modelo en la generalización de las dos clases que resultaron ser 74%.,
model_score = model.score(X_test, y_test)model_score

la Evaluación del modelo

Roc_score
- Importados de las auc, roc_curve de nuevo desde sklearn.métricas.
- puntuación roc_auc impresa entre falso positivo y verdadero positivo que resultó ser del 79%.
- Matplotlib importado.biblioteca pyplot para trazar el roc_curve.
- imprimió el roc_curve.,
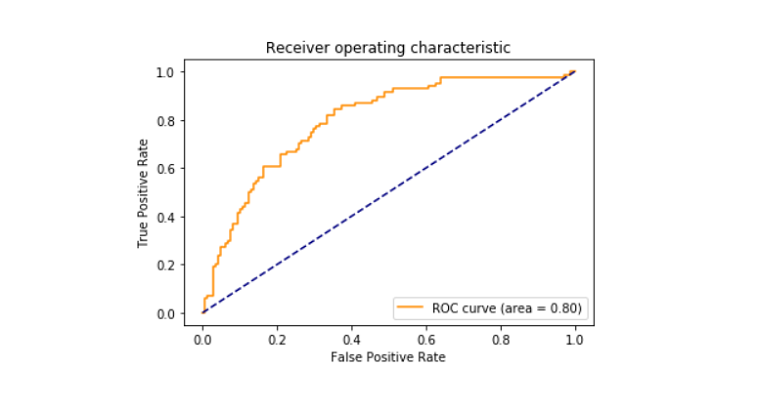
Roc_curve
El receptor de la curva característica de operación también conocido como roc_curve es una trama que se nos dice acerca de la interpretación del potencial de un sistema clasificador binario. Se traza entre la tasa positiva verdadera y la tasa positiva falsa en diferentes umbrales. El área de la curva ROC fue de 0,80.
para el archivo python y también el conjunto de datos utilizado en el problema anterior, puede consultar el enlace de Github aquí que contiene ambos.,
conclusión
en este blog, he hablado de Algoritmos Bayes ingenuos utilizados para tareas de clasificación en diferentes contextos. He discutido Cuál es el papel del teorema de Bayes en el clasificador de NB, diferentes características de NB, ventajas y desventajas de NB, aplicación de NB, y en el último he tomado una declaración de problema de Kaggle que se trata de clasificar a los pacientes como diabéticos o no.