considérez un cas où vous avez créé des entités, vous connaissez l’importance des entités et vous êtes censé faire un modèle de classification qui doit être présenté dans un très court laps de temps?
Qu’allez-vous faire? Vous avez un très grand volume de points de données et très peu de fonctionnalités dans votre ensemble de données., Dans cette situation, si j’avais dû faire un tel modèle, j’aurais utilisé ‘Naive Bayes’, qui est considéré comme un algorithme très rapide lorsqu’il s’agit de tâches de classification.
dans ce blog, j’essaie d’expliquer comment fonctionne l’algorithme qui peut être utilisé dans ce genre de scénarios. Si vous voulez savoir ce qu’est la classification et d’autres algorithmes de ce type, vous pouvez vous référer ici.
Naive Bayes est un modèle d’apprentissage automatique utilisé pour de gros volumes de données, même si vous travaillez avec des données contenant des millions d’enregistrements de données, L’approche recommandée est Naive Bayes., Il donne de très bons résultats en ce qui concerne les tâches de PNL telles que l’analyse sentimentale. C’est un algorithme de classification rapide et simple.
pour comprendre le classificateur naïf de Bayes, nous devons comprendre le théorème de Bayes. Discutons donc d’abord du théorème de Bayes.
Théorème de Bayes
C’est un théorème qui travaille sur les probabilités conditionnelles. La probabilité conditionnelle est la probabilité que quelque chose se produise, étant donné que quelque chose d’autre s’est déjà produit. La probabilité conditionnelle peut nous donner la probabilité d’un événement en utilisant sa connaissance préalable.,
probabilité Conditionnelle:
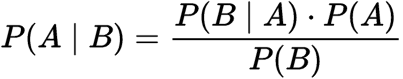
Probabilité Conditionnelle
Où
P(A): La probabilité de l’hypothèse H étant vrai. Ceci est connu comme la probabilité antérieure.
P(B): La probabilité de la preuve.
P(A|B): La probabilité de la preuve, étant donné que l’hypothèse est vraie.
P(B|A): la probabilité de l’hypothèse étant donné que la preuve est vraie.
Naïf Classificateur de Bayes
-
C’est une sorte de classificateur qui fonctionne sur le théorème de Bayes.,
-
La Prédiction des probabilités d’appartenance est faite pour chaque classe, par exemple la probabilité de points de données associés à une classe particulière.
-
La classe ayant la probabilité maximale est évaluée comme la classe la plus appropriée.
- Ceci est également appelé Maximum a Posteriori (MAP).
-
NB les classificateurs concluent que toutes les variables ou caractéristiques ne sont pas liées les unes aux autres.
-
L’Existence ou l’absence d’une variable n’a pas d’incidence sur l’existence ou de l’absence de toute autre variable.,
-
Exemple:
-
un Fruit peut être observée à être une pomme si elle est rouge, ronde, et d’environ 4″ de diamètre.
-
dans ce cas aussi, même si toutes les caractéristiques sont interdépendantes les unes aux autres, et NB Classificateur observera tous ces indépendamment contribuant à la probabilité que le fruit est une pomme.
-
-
nous expérimentons l’hypothèse dans des ensembles de données réels, compte tenu de plusieurs caractéristiques.
-
Donc, le calcul devient complexe.
types D’algorithmes Bayes naïfs
1., Bayes naïves gaussiennes: lorsque les valeurs caractéristiques sont continues dans la nature alors on suppose que les valeurs liées à chaque classe sont dispersées selon gaussienne qui est la Distribution normale.
2. Bayes naïves multinomiales: les Bayes naïves Multinomiales sont favorisées pour être utilisées sur des données distribuées multinomiales. Il est largement utilisé dans la classification de texte en PNL. Chaque événement dans la classification de textes constitue la présence d’un mot dans un document.
3., Bernoulli Naïve Bayes: lorsque les données sont distribuées selon les distributions de Bernoulli multivariées, Bernoulli naïve Bayes est utilisé. Cela signifie qu’il existe plusieurs fonctionnalités, mais chacune est supposée contenir une valeur binaire. Donc, cela nécessite que les fonctionnalités soient à valeur binaire.
avantages et inconvénients de Naive Bayes
avantages:
-
c’est un algorithme très extensible qui est très rapide.
-
Il peut être utilisé pour les fichiers binaires ainsi que multiclasse.,
-
Il a principalement trois types d’algorithmes différents qui sont GaussianNB, MultinomialNB, BernoulliNB.
-
c’est un algorithme célèbre pour la classification des spams.
-
Il peut être facilement formés sur les petits jeux de données et peut être utilisé pour de gros volumes de données.
inconvénients:
-
le principal inconvénient du NB est de considérer toutes les variables indépendantes qui contribuent à la probabilité.,
Applications des algorithmes naïfs de Bayes
-
prédiction en temps réel: être un algorithme d’apprentissage rapide peut également être utilisé pour faire des prédictions en temps réel.
-
Classification multiclasse: il peut également être utilisé pour des problèmes de classification multiclasse.
-
classification de texte: comme il a montré de bons résultats dans la prédiction de la classification multi-classes, il a donc plus de taux de réussite par rapport à tous les autres algorithmes. En conséquence, il est principalement utilisé dans l’analyse des sentiments & détection de spam.,
énoncé pratique du problème
l’énoncé du problème consiste à classer les patients comme diabétiques ou non diabétiques. L’ensemble de données peut être téléchargé à partir du site Web de Kaggle qui est « Pima INDIAN DIABETES DATABASE ». Les ensembles de données avaient plusieurs caractéristiques prédictives médicales différentes et une cible qui est le « résultat ». Les variables prédictives comprennent le nombre de grossesses que la patiente a eues, son IMC, son taux d’insuline, son âge, etc.,
implémentation du code d’importation et de fractionnement des données
étapes-
- Initialement, toutes les bibliothèques nécessaires sont importées comme numpy, pandas, train-test_split, GaussianNB, metrics.
- comme il s’agit d’un fichier de données sans en-tête, nous fournirons les noms de colonnes qui ont été obtenus à partir de l’URL ci-dessus
- a créé une liste python de noms de colonnes appelée « noms ».
- variables prédictives initialisées et la cible qui est X et Y respectivement.
- a transformé les données à L’aide de StandardScaler.,
- divisez les données en ensembles d’entraînement et de test.
- a créé un objet pour GaussianNB.
- a ajusté les données dans le modèle pour les entraîner.
- a fait des prédictions sur l’ensemble de tests et les a stockées dans une variable ‘predictor’.
Pour faire l’analyse exploratoire des données de l’ensemble de données, vous pouvez rechercher les techniques.

Confusion-matrice & modèle de score de données de test
- Importé accuracy_score et confusion_matrix de sklearn.métrique., Imprimé la matrice de confusion entre prédit et réel qui nous indique les performances réelles du modèle.
- a calculé le model_score des données de test pour savoir à quel point le modèle est performant dans la généralisation des deux classes qui sont ressorties à 74%.,
model_score = model.score(X_test, y_test)model_score

l’Évaluation du modèle

Roc_score
- Importé de l’asc, roc_curve à nouveau à partir de sklearn.métrique.
- score roc_auc imprimé entre faux positif et vrai positif qui est ressorti à 79%.
- matplotlib importé.bibliothèque pyplot pour tracer le roc_curve.
- Imprimé le roc_curve.,
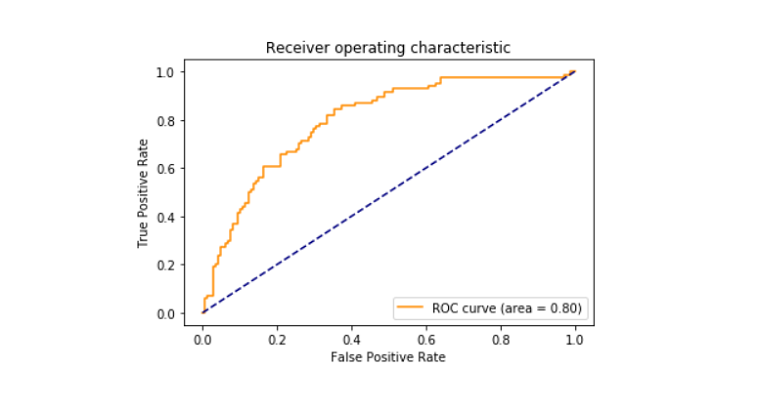
Roc_curve
La caractéristique de fonctionnement du récepteur de la courbe aussi connu comme roc_curve est un complot qui raconte l’interprétation potentiel d’un classificateur binaire du système. Il est tracé entre le taux vrai positif et le taux faux positif à différents seuils. La surface de la courbe ROC s’est avérée être de 0,80.
pour le fichier python et l’ensemble de données utilisé dans le problème ci-dessus, vous pouvez vous référer au lien Github ici qui contient les deux.,
Conclusion
dans ce blog, j’ai discuté des algorithmes naïfs de Bayes utilisés pour des tâches de classification dans différents contextes. J’ai discuté du rôle du théorème de Bayes dans le classificateur NB, des différentes caractéristiques du NB, des avantages et des inconvénients du NB, de L’application du NB, et dans le dernier, j’ai pris une déclaration de problème de Kaggle qui consiste à classer les patients diabétiques ou non.