rozważ przypadek, w którym stworzyłeś funkcje, wiesz o znaczeniu funkcji i masz stworzyć model klasyfikacji, który ma być przedstawiony w bardzo krótkim czasie?
Co zrobisz? Masz bardzo dużą ilość punktów danych i bardzo mało funkcji w zestawie danych., W takiej sytuacji, gdybym miał zrobić taki model, użyłbym „naiwnego Bayesa”, który jest uważany za bardzo szybki algorytm, jeśli chodzi o zadania klasyfikacyjne.
w tym blogu staram się wyjaśnić, jak działa algorytm, który może być stosowany w tego typu scenariuszach. Jeśli chcesz wiedzieć, czym jest klasyfikacja i inne tego typu algorytmy, możesz odnieść się tutaj.
Naive Bayes jest modelem uczenia maszynowego, który jest używany do dużych ilości danych, nawet jeśli pracujesz z danymi, które mają miliony rekordów danych, zalecanym podejściem jest Naive Bayes., Daje bardzo dobre wyniki jeśli chodzi o zadania NLP takie jak analiza sentymentalna. Jest to szybki i nieskomplikowany algorytm klasyfikacji.
aby zrozumieć naiwny klasyfikator Bayesa musimy zrozumieć twierdzenie Bayesa. Więc najpierw omówmy twierdzenie Bayesa.
twierdzenie Bayesa
jest to twierdzenie, które działa na prawdopodobieństwo warunkowe. Prawdopodobieństwo warunkowe to prawdopodobieństwo, że coś się wydarzy, biorąc pod uwagę, że coś innego już się wydarzyło. Prawdopodobieństwo warunkowe może dać nam prawdopodobieństwo zdarzenia przy użyciu jego wcześniejszej wiedzy.,
prawdopodobieństwo warunkowe:
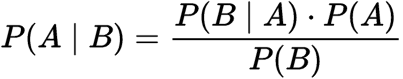
prawdopodobieństwo warunkowe
Gdzie,
p(a): prawdopodobieństwo hipotezy H jest prawdziwe. Jest to znane jako wcześniejsze prawdopodobieństwo.
p(B): prawdopodobieństwo dowodu.
P(A / B): prawdopodobieństwo udowodnienia, że hipoteza jest prawdziwa.
P(B / A): prawdopodobieństwo hipotezy, biorąc pod uwagę, że dowody są prawdziwe.
Naive Bayes Classifier
-
jest to rodzaj klasyfikatora, który działa na twierdzeniu Bayesa.,
-
Przewidywanie prawdopodobieństwa członkostwa jest dokonywane dla każdej klasy, takie jak prawdopodobieństwo punktów danych związanych z daną klasą.
-
Klasa o maksymalnym prawdopodobieństwie jest oceniana jako najbardziej odpowiednia.
- jest to również określane jako Maximum a Posteriori (Mapa).
-
klasyfikatory NB stwierdzają, że wszystkie zmienne lub funkcje nie są ze sobą powiązane.
-
istnienie lub brak zmiennej nie ma wpływu na istnienie lub brak innej zmiennej.,
-
przykład:
-
owoc może być jabłkiem, jeśli jest czerwony, okrągły i około 4″ średnicy.
-
w tym przypadku również, nawet jeśli wszystkie cechy są ze sobą powiązane, a klasyfikator NB zaobserwuje je wszystkie niezależnie przyczyniając się do prawdopodobieństwa, że owoc jest jabłkiem.
-
-
eksperymentujemy z hipotezą w rzeczywistych zestawach danych, biorąc pod uwagę wiele funkcji.
-
tak więc obliczenia stają się skomplikowane.
typy naiwnych algorytmów Bayesa
1., Gaussian naiwne Bayes: gdy wartości charakterystyczne są ciągłe w naturze, to zakłada się, że wartości związane z każdej klasy są rozproszone zgodnie z Gaussian, który jest rozkładem normalnym.
2. Wielomian naiwny Bayes: wielomian naiwny Bayes jest preferowane do wykorzystania na danych, które są wielomian rozproszone. Jest szeroko stosowany w klasyfikacji tekstu w NLP. Każde zdarzenie w klasyfikacji tekstu stanowi obecność słowa w dokumencie.
3., Bernoulli Naive Bayes: gdy dane są przekazywane zgodnie z wielowymiarowymi dystrybucjami Bernoulliego, to Bernoulli Naive Bayes jest używany. Oznacza to, że istnieje wiele funkcji, ale zakłada się, że każda z nich zawiera wartość binarną. Wymaga więc, aby funkcje były wartościami binarnymi.
zalety i wady naiwnego Bayesa
zalety:
-
jest to wysoce rozszerzalny algorytm, który jest bardzo szybki.
-
może być używany zarówno dla binariów, jak i klasyfikacji wieloklasowej.,
-
ma głównie trzy różne typy algorytmów, które są GaussianNB, MultinomialNB, BernoulliNB.
-
jest to znany algorytm klasyfikacji spamu.
-
można go łatwo trenować na małych zestawach danych i może być również używany do dużych ilości danych.
wady:
-
główną wadą NB jest uwzględnienie wszystkich zmiennych niezależnych, które przyczyniają się do prawdopodobieństwa.,
zastosowania naiwnych algorytmów Bayesa
-
przewidywanie w czasie rzeczywistym: jako algorytm szybkiego uczenia się może być również używany do przewidywania w czasie rzeczywistym.
-
Klasyfikacja Wieloklasowa: może być również używana do problemów z klasyfikacją wielu klas.
-
Klasyfikacja tekstu: ponieważ wykazała dobre wyniki w przewidywaniu klasyfikacji wieloklasowej, dzięki czemu ma większą skuteczność w porównaniu do wszystkich innych algorytmów. W rezultacie jest głównie używany w analizie nastrojów & wykrywanie spamu.,
praktyczne Oświadczenie o problemie
Oświadczenie o problemie polega na sklasyfikowaniu pacjentów jako chorych na cukrzycę lub bez cukrzycy. Zbiór danych można pobrać ze strony internetowej Kaggle, która jest „Pima INDIAN DIABETES DATABASE”. Zestawy danych miały kilka różnych medycznych predyktorów i cel, który jest „wynik”. Zmienne predykcyjne obejmują liczbę ciąż pacjent miał, ich BMI, poziom insuliny, wiek, i tak dalej.,
implementacja kodu importowania i dzielenia danych
kroki-
- Początkowo wszystkie niezbędne biblioteki są importowane jak numpy, pandas, train-test_split, GaussianNB, metrics.
- ponieważ jest to plik danych bez nagłówka, podamy nazwy kolumn, które zostały uzyskane z powyższego adresu URL
- stworzył pythonową listę nazw kolumn o nazwie „names”.
- zainicjalizowane zmienne predykcyjne i cel, który jest odpowiednio X i Y.
- przetworzył dane przy użyciu StandardScaler.,
- podziel dane na zestawy treningowe i testowe.
- stworzył obiekt dla GaussianNB.
- wykonał prognozy na zestawie testowym i zapisał go w zmiennej „predictor”.
do wykonywania analizy danych eksploracyjnych zbioru danych można szukać technik.

Confusion-matrix & dane testu wyniku modelu
- zaimportowane dokładne_przyciski i confusion_matrix z sklearn.metryki., Wydrukowano matrycę zamieszania między przewidywanym i rzeczywistym, która mówi nam o rzeczywistej wydajności modelu.
- obliczył model_score danych testowych, aby wiedzieć, jak dobry jest model w uogólnianiu dwóch klas, które okazały się być 74%.,
model_score = model.score(X_test, y_test)model_score

ocena modelu

roc_score
- importowane AUC, roc_curve ponownie ze sklepu.metryki.
- Wydrukowano wynik roc_auc pomiędzy false positive i true positive, który okazał się być 79%.
- importowany matplotlib.biblioteka pyplot do wykreślenia roc_curve.
- wydrukował roc_curve.,
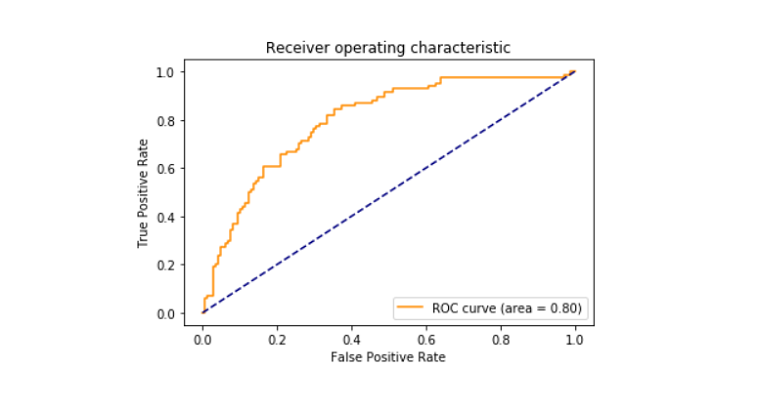
Roc_curve
krzywa charakterystyki pracy odbiornika znana również jako roc_curve jest wykresem, który mówi o potencjale interpretacyjnym binarnego systemu klasyfikatora. Jest ona wykreślana między rzeczywistym wskaźnikiem dodatnim a fałszywym wskaźnikiem dodatnim w różnych progach. Obszar krzywej ROC ustalono na 0,80.
dla pliku Pythona, a także używanego zestawu danych w powyższym problemie możesz odwołać się do linku Github, który zawiera oba.,
podsumowanie
w tym blogu omówiłem naiwne algorytmy Bayesa używane do zadań klasyfikacyjnych w różnych kontekstach. Omówiłem, jaka jest rola twierdzenia Bayesa w klasyfikacji NB, różne cechy NB, zalety i wady NB, zastosowanie NB, a w ostatnim wziąłem problem stwierdzenie z Kaggle, że jest o klasyfikacji pacjentów jako cukrzycy, czy nie.