Projektowanie i budowa randomizowanych bibliotek dla assaying Cas9 Pam preferences
biblioteki Pam zawierające randomizowane sekwencje DNA bezpośrednio za sekwencją DNA komplementarną do przekładki przewodnika RNA zostały wygenerowane i wykorzystane do empirycznego określenia rozpoznawania Pam endonukleaz typu II Cas9 (rys. 1)., Z ustaloną sekwencją docelową RNA dystansowego, randomizowane Zasady służą jako substrat do bezpośredniego odczytu specyficzności endonukleazy Pam Cas9. Randomizowane sekwencje zostały wprowadzone do wektora plazmidowego DNA w regionie Pam protospacerowej sekwencji docelowej wykazującej idealną homologię do przewodnika RNA spacer T1 (CGCUAAAGAGGACA). Wygenerowano dwie biblioteki zwiększające rozmiar i złożoność z pięciu randomizowanych par bazowych (1024 potencjalne kombinacje Pam) do siedmiu randomizowanych par bazowych (16 384 potencjalne kombinacje Pam)., Randomizację biblioteki 5 bp wprowadzono poprzez syntezę pojedynczego oligonukleotydu zawierającego pięć przypadkowych reszt. Jednoniciowy oligonukleotyd został przekształcony w dwuniciowy szablon przez PCR (dodatkowy plik 1: Rysunek S1A), sklonowany do wektora plazmidu (dodatkowy plik 1: Rysunek S1B) i przekształcony w E. coli, jak opisano w sekcji Metody., Aby zapewnić optymalną losowość w bibliotece 7 bp Pam, rozmiar i złożoność biblioteki zostały zmniejszone przez syntezę czterech oligonukleotydów, z których każdy zawiera sześć przypadkowych pozostałości plus siódma stała pozostałość zawierająca odpowiednio G, C, A lub T. Każdy z czterech oligonukleotydów został osobno przekształcony w dwuniciowe DNA, sklonowany do wektora pTZ57R / T, jak opisano w sekcji Metody i przekształcony w E. coli, jak opisano dla biblioteki 5 bp., Po transformacji plazmid DNA został odzyskany i połączony z każdej z czterech bibliotek Pam 6 bp w celu wygenerowania randomizowanej biblioteki Pam 7 bp zawierającej 16 384 możliwych kombinacji Pam. Dla obu bibliotek, inkorporacja randomness zatwierdzał głębokiego sekwencjonowania; badając nucleotide skład w każdej pozycji Pam region używać pozycyjny częstotliwość matryca (PFM) (metody sekcja i) (dodatkowy kartoteka 1: Rysunek S2A i B)., Rozkład i częstotliwość każdej sekwencji PAM w randomizowanej bibliotece Pam 5 bp i 7 bp są pokazane w dodatkowym pliku 1: rysunki S3 i S4, odpowiednio.
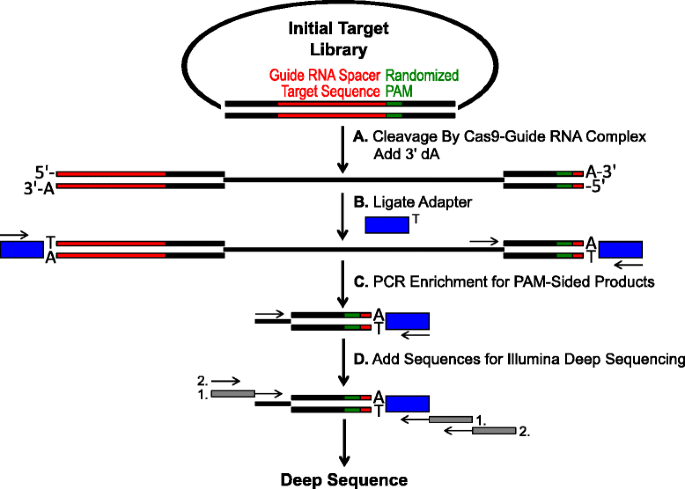
schemat identyfikacji preferencji PAM za pomocą rozszczepienia Cas9 in vitro. początkowa biblioteka plazmidów z randomizowanym PAM (zielone pudełko) jest rozszczepiona kompleksem Cas9 i dodaje się zwisy 3′ dA. Adaptery b z nawisem 3′ dT (blue box) są podwiązane do obu końców produktu dekoltu., podkłady c są wykorzystywane do wzbogacania produktów Pam-jednostronnie rozszczepianych przez PCR., d po wzbogaceniu PCR fragmenty DNA są oczyszczane, a kotwy i kody kreskowe kompatybilne z Illumina są”ogoniaste”przez dwie rundy PCR (szare pudełka) i głęboko sekwencjonowane Illumina
oznaczanie preferencji Cas9 pam
randomizowane biblioteki PAM opisane w poprzedniej sekcji zostały poddane trawieniu in vitro z różnymi stężeniami rekombinowanego białka Cas9 wstępnie załadowanego z przewodnikiem RNA w celu oznaczania preferencji endonukleazy Cas9 PAM w sposób zależny od dawki., Po trawieniu kompleksami rybonukleoproteiny RNA RNP (Cas9-guide RNA), sekwencje Pam z randomizowanej biblioteki PAM, które wspierały rozszczepienie, zostały przechwycone przez wiązanie adapterów do wolnych końców cząsteczek plazmidu DNA rozszczepionych przez kompleks RNA Cas9-guide (rys. 1a i b). Aby promować efektywne ligowanie i wychwytywanie rozszczepionych końców, tępo zakończone dwuniciowe cięcie DNA generowane przez endonukleazy Cas9 zmodyfikowano tak, aby zawierały zwis 3 'dA, a Adaptery zmodyfikowano tak, aby zawierały komplementarny zwis 3′ dT., Aby wygenerować wystarczającą ilość DNA do sekwencjonowania, fragmenty DNA zawierające sekwencję Pam wspierającą rozszczepienie zostały wzmocnione PCR za pomocą podkładu w adapterze i innego bezpośrednio przylegającego do regionu PAM (rys. 1c). Powstałe biblioteki Pam PCR wzmocnione Cas9 zostały przekształcone w szablony ampli-seq (rys. 1d) i jednokrotnego odczytu głębokiego sekwencjonowanego od strony adaptera amplikonu., Aby zapewnić odpowiedni zasięg, Biblioteki Cas9 Pam zostały uporządkowane do głębokości co najmniej pięć razy większej niż różnorodność w początkowej randomizowanej bibliotece PAM(odpowiednio 5 120 i 81 920 odczytów dla 5 i 7 bp Pam randomizowanych bibliotek). Sekwencje Pam zidentyfikowano na podstawie uzyskanych danych sekwencji, wybierając tylko te odczyty zawierające idealną sekwencję 12 nt dopasowaną po obu stronach sekwencji 5 lub 7 nt PAM (w zależności od użytej randomizowanej biblioteki Pam); przechwytywanie tylko tych sekwencji Pam wynikających z doskonałego rozpoznawania i rozszczepiania RNA-guide Cas9., Aby skompensować nieodłączne odchylenia w początkowych randomizowanych bibliotekach PAM, częstotliwość każdej sekwencji Pam została znormalizowana do jej częstotliwości w bibliotece startowej. Ponieważ opisywany tu test bezpośrednio rejestruje rozszczepialne sekwencje Pam Cas9, modelowanie probabilistyczne zostało wykorzystane do obliczenia konsensusu Pam dla każdego białka Cas9. Udało się to osiągnąć poprzez ocenę prawdopodobieństwa znalezienia każdego nukleotydu (G, C, A lub T) w każdej pozycji sekwencji Pam niezależnie za pomocą macierzy częstotliwości pozycyjnej (PFM) (sekcja metod i)., Powstałe prawdopodobieństwo zostało następnie wizualizowane jako WebLogo .
aby zbadać skłonność do fałszywie dodatnich wyników w teście, pominięto dodanie kompleksów Cas9 RNP w etapie trawienia (rys. 1a) i test przeprowadzono poprzez etap wzbogacania PCR (rys. 1c). Jak pokazano w dodatkowym pliku 1: Rysunek S5A, nie wykryto produktów amplifikacji w absense kompleksów RNA Cas9-guide. Tak więc, wskazując, że częstość występowania fałszywie dodatnich jest niska i nie przyczynia się znacząco do wyników testu.,
preferencje Pam dla Streptococcus pyogenes i Streptococcus thermophilus (CRISPR3 i CRISPR1) białka Cas9
w celu walidacji testu zbadano preferencje Pam dla Streptococcus pyogenes (Spy) i Streptococcus thermophilus CRISPR3 (Sth3) białka Cas9, których wcześniej zgłoszono zapotrzebowanie na sekwencję Pam. W badaniach in vitro przeprowadzono 1 µg (5,6 nM) randomizowanej biblioteki PAM 5 bp w dwóch stężeniach, 0,5 i 50 nM, wstępnie zmontowanych kompleksów białka Spy lub Sth3 Cas9, crRNA i tracrRNA RNP przez 1 h W 100 µL objętości reakcji., Na podstawie ich częstości w randomizowanej bibliotece PAM 5 bp, sekwencje Pam Spy i Sth3 Cas9 (odpowiednio NGG i NGGNG) były w końcowych stężeniach odpowiednio 0,40 nM i 0,11 nM w trawieniu. Członkowie randomizowanej biblioteki PAM, która zawierała sekwencje Pam, które wspierały rozszczepienie, zostali przechwyceni i zidentyfikowani zgodnie z opisem w poprzedniej sekcji. Jako kontrola negatywna, początkowa niezakłócona randomizowana biblioteka PAM była poddawana sekwencjonowaniu i analizie PFM wraz z bibliotekami narażonymi na kompleksy Cas9 RNP., Jak pokazano w dodatkowym pliku 1: Rysunek S5B i C, nie istnieją preferencje sekwencji w przypadku braku kompleksowego trawienia Cas9 RNP, o czym świadczy prawie doskonały rozkład każdego nukleotydu w każdej pozycji PAM w tabeli PFM i brak treści informacyjnej w WebLogo dla kontroli. To jest w surowej interpretacji z Rys. 2a i b, które ilustrują skład sekwencji pochodzących z bibliotek strawionych kompleksami Spy i Sth3 Cas9 RNP. Badanie PFM pochodnej WebLogos (rys., 2a i b) ujawniają również obecność kanonicznych preferencji PAM dla białek Spy i Sth3 Cas9, odpowiednio NGG i NGGNG. Chociaż preferencje Pam zgłaszane dla białek Spy i Sth3 Cas9 są obserwowane zarówno w strawach 0,5 nM, jak i 50 nM, w Warunkach strawienia 50 nM obserwuje się ogólne poszerzenie swoistości. Jest to najbardziej widoczne w pozycji 2 dla białka Spy Cas9, gdzie częstotliwość niekanonicznej pozostałości a wzrasta dramatycznie (rys. 2A)., For Sth3, all PAM positions exhibit a marked decrease in specificity as a result of increasing the RNP complex concentration (Fig. 2b).
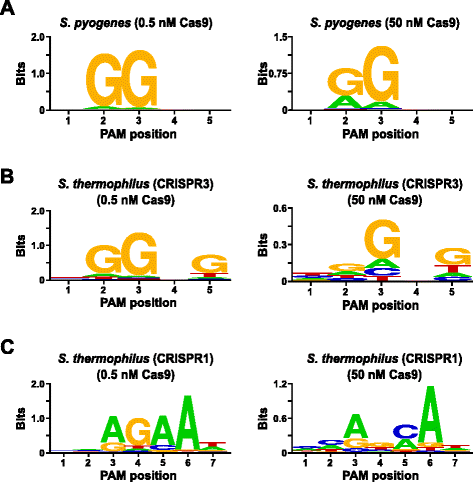
PAM preferences for S. pyogenes (a), S. thermophilus CRISPR3 (b), and S. thermophilus CRISPR1 (c) Cas9 proteins., Częstotliwość nukleotydów w każdej pozycji PAM została niezależnie obliczona przy użyciu matrycy częstotliwości pozycyjnej (PFM) i wykreślona jako WebLogo
dalsza Walidacja testu została przeprowadzona przez zbadanie preferencji Pam dla białka Cas9 Streptococcus thermophilus (Sth1), którego specyficzność Pam została zgłoszona do 7 bp . Używając 1 µg (5,6 nM) randomizowanej biblioteki pam 7 bp jako szablonu, sth1 Cas9-guide RNA digestions przeprowadzono w dwóch stężeniach, 0,5 nM i 50 nM, kompleksu RNP, jak opisano powyżej., Jako kontrolery, kompleksy Spy i Sth3 Cas9 RNP były również używane do trawienia randomizowanej biblioteki pam 7 bp, ale tylko w pojedynczym, 0,5 nM, stężeniu kompleksu RNP. Na podstawie częstości w randomizowanej bibliotece Pam 7 bp, sekwencje Pam wcześniej zgłaszane dla Sth1( NNAGAAW), Spy (NGG) i Sth3 (NGGNG) były w końcowych stężeniach odpowiednio 0,01 nM, 0,22 nM i 0,05 nM., Jak pokazano w dodatkowym pliku 1: Rysunek S6A i B, preferencje Pam dla białek Spy i Sth3 Cas9 generowanych przy użyciu biblioteki 7 bp były prawie identyczne do tych wytwarzanych przy użyciu biblioteki 5 bp dostarczając silnych dowodów na odtwarzalność testu. Preferencje Pam dla białka Sth1 Cas9 również ściśle pasowały do wcześniej zgłaszanego, NNAGAAW, przy stężeniu kompleksu RNA-przewodnika 0,5 nM (rys. 2c)., Podobnie jak białka Spy i Sth3 Cas9, sth1 Cas9 był w stanie rozszczepić bardziej zróżnicowany zestaw sekwencji PAM w reakcjach zawierających wyższe stężenie kompleksu RNA-przewodnika Cas9 (50 nM), najbardziej uderzające było wyraźne zmniejszenie zapotrzebowania na pozostałości G w pozycji 4 i prawie równe preferencje dla C i bp w pozycji 5 (rys. 2c). Spowodowało to inny konsensus PAM niż uzyskany w niższych stężeniach.,
aby sprawdzić, czy specyficzność PAM jest niezależna od typu przewodnika RNA , zbadano również dupleks crRNA:tracrRNA lub sgRNA, Spy, Sth3 i Sth1 preferencje Cas9 Pam przy użyciu kompleksu binarnego Cas9 i sgRNA RNP. Trawienie przeprowadzono przy pojedynczym stężeniu kompleksu RNP wynoszącym 0,5 nM, a analizę preferencji Pam przeprowadzono jak opisano powyżej. Jak pokazano w dodatkowym pliku 1: Rysunek S7A, B I C, preferencje PAM były prawie identyczne niezależnie od rodzaju użytego przewodnika RNA; albo crrna: tracrrna duplex lub sgRNA., Ponadto, aby potwierdzić, że specyficzność Pam nie ma dużego wpływu na skład docelowego DNA lub sekwencji dystansowej, Sekwencja po przeciwnej stronie randomizowanej biblioteki 5 lub 7 bp została ukierunkowana na rozcięcie z inną ramką; T2 – 5 (UCUAGAUAGAUUACGAAUUC) dla biblioteki 5 bp lub T2-7 (CCGGCGACGUUGGGUCAACU) dla biblioteki 7 bp. Spy i sth3 Cas9 proteiny fabrycznie załadowane sgRNAs celujący sekwencję T2 były używane do przesłuchiwania 5 bp randomizowanej biblioteki PAM, podczas gdy sth1 Cas9-T2 sgRNA kompleksy były używane do trawienia 7 bp randomizowanej biblioteki PAM., Preferencje PAM zostały zbadane w sposób opisany powyżej. Preferencje Pam dla wszystkich 3 białek Cas9 były prawie identyczne niezależnie od odstępu i docelowej sekwencji DNA (dodatkowy plik 1: Rysunek S8A, B I C).
Identyfikacja preferencji sgRNA i PAM dla białka Brevibacillus lateosporus Cas9
aby empirycznie zbadać preferencje Pam dla białka Cas9, którego Pam był niezdefiniowany, uncharacterized Type II-C CRISPR-Cas locus od Brevibacillus lateosporus szczep SSP360D4 (Blat) został zidentyfikowany przez przeszukiwanie wewnętrznych baz danych Pioneer DuPont w poszukiwaniu ortologów Cas9., Locus (około 4,5 kb) zawierał Gen cas9 zdolny do kodowania polipeptydu 1,092, tablicę CRISPR składającą się z siedmiu jednostek powtarzających się tuż za genem cas9 i region kodujący tracrRNA znajdujący się przed genem cas9 z częściową homologią do powtórzeń tablicy CRISPR (rys. 3a). Długość powtórzeń i odstępów (odpowiednio 36 i 30 bp) jest podobna do innych systemów CRISPR-Cas typu II z pięcioma z ośmiu powtórzeń zawierających 1 lub 2 mutacje bp (rys. 3b i dodatkowy plik 1: Rysunek S9)., Inne geny typowo znalezione W Typ II CRISPR-Cas locus były albo obcięte (cas1)lub brakujące (rys. 3a).
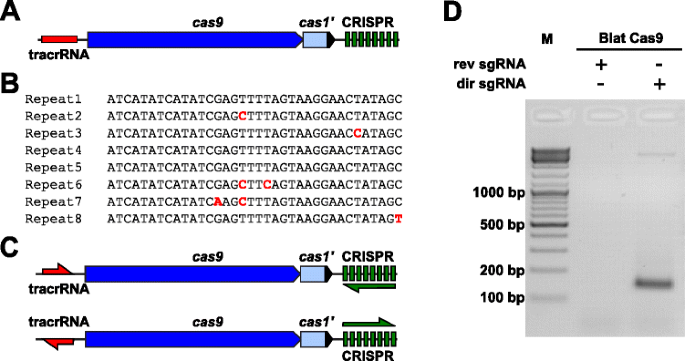
Identyfikacja elementów CRISPR-Cas typu II w systemie Brevibacillus laterosporus ssp360d4 CRISPR-Cas. a ilustracja genomicznego regionu DNA z systemu CRISPR-Cas typu II z Brevibacillus lateosporus SSP360D4. b porównanie sekwencji powtórzeń typu II CRISPR zidentyfikowanych w Brevibacillus lateosporus SSP360D4., c scenariusze transkrypcyjne „direct” i „reverse” tracrna i CRISPR dla systemu CRISPR-Cas typu II z Brevibacillus lateosporus SSP360D4. d żel agarozowy z produktami reakcji, co wskazuje, że tylko”bezpośredni”sgRNA (dir sgRNA), ale nie „odwrotny” sgRNA (rev sgRNA) wspierają rozszczepienie biblioteki plazmidów w połączeniu z endonukleazą Cas9 pochodzącą z Brevibacillus lateosporus SSP360D4
po określeniu odpowiedniego RNA prowadzącego dla Blat Cas9, identyfikacja PAM została przeprowadzona podobnie jak opisana powyżej dla białek Spy, Sth3 i Sth1 Cas9 wobec randomizowanej biblioteki pam 7 bp o dwóch stężeniach, 0,5 i 50 nM, wstępnie zmontowanego kompleksu blat Cas9 'direct' sgRNA RNP. Jak pokazano na Rys. 4A, konsensus PFM WEBLOGO Pam dla białka blat Cas9 w Warunkach fermentacji 0,5 nM wynosił NNNNCND (N = G, C, A lub T; D = A, G lub T) z silną preferencją dla C w pozycji 5 sekwencji PAM., Umiarkowane preferencje dla a zaobserwowano w pozycji 7 i niewielkie preferencje dla C lub T w pozycji 4 i G, C, lub a ponad T w pozycji 6 odnotowano również podczas dokładnego badania tabeli PFM (dodatkowy plik 1: Rysunek S11). Podobnie jak białka Spy, Sth3 i Sth1 Cas9, specyficzność Pam rozszerza się wraz ze wzrostem stężenia kompleksu Cas9-sgRNA. Jest to najbardziej widoczne w pozycji 5, gdzie większa część sekwencji Pam zawierających pozostałość A wspiera rozszczepienie przy 50 nM w porównaniu z warunkami trawienia 0,5 nM.
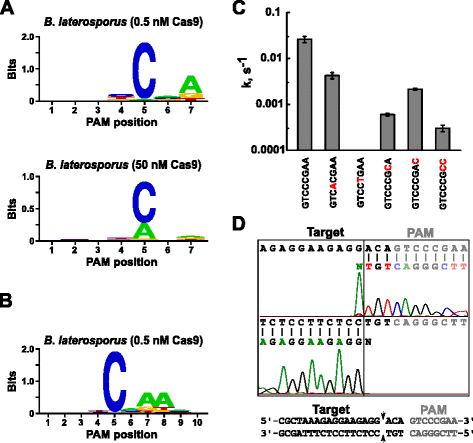
preferencje PAM i pozycje rozszczepienia enzymu Brevibacillus lateosporus SSP360D4 (Blat) Cas9. Blat Cas9 Pam preferuje, gdy 1 µg DNA biblioteki został rozszczepiony o 0,5 nM lub 50 nM Kompleks Cas9-sgRNA (a), Rozszerzony do pozycji 10 przez przesunięcie celu protospacera o 3 bp (b). Częstotliwość nukleotydów w każdej pozycji Pam została niezależnie obliczona przy użyciu matrycy częstotliwości pozycyjnej (PFM) i wykreślona jako WebLogo ., c tempo rozszczepienia nadpłytkowych substratów plazmidowego DNA zawierających mutacje (pokazane na Czerwono) w sekwencji PAM GTCCCGAA. Wszystkie punkty danych są wartości średnie z ≥3 niezależnych eksperymentów. Paski błędów są podane jako sekwencjonowanie S. D. D z kierunków sense i anty-sense plazmidowego DNA rozszczepionego z blat Cas9
ponieważ Blat Cas9 może przyjąć dowolną bazę w trzech pierwszych pozycjach swojej sekwencji PAM (rys. 4A), dystans T1 został przesunięty o trzy nukleotydy w kierunku 5′, aby umożliwić wydłużenie identyfikacji PAM z 7 do 10 bp., Przesunięta przekładka T1, T1 – 3 (AAACGCUAAAGAGG), została włączona do blat „direct” sgRNA, a identyfikacja PAM została przeprowadzona zgodnie z opisem wcześniej dla białek Spy, Sth3, Sth1 i blat Cas9. Analiza preferencji Pam wykazała, że specyficzność Pam dla Blat Cas9 może zostać rozszerzona do pozycji 8, gdzie istnieje umiarkowana preferencja dla dodatkowego A (rys. 4b).
specyficzność Pam dla Blat Cas9 została potwierdzona przez generowanie plazmidów zawierających mutacje w najbardziej zachowanych resztach Pam (rys. 4c)., Zastąpienie nukleotydu C w pozycji 5 zniosło rozszczepienie plazmidu DNA potwierdzając jego kluczową rolę w rozpoznawaniu Blat Cas9 PAM. Zastąpienie nukleotydów w pozycjach 7 i 8 znacznie zmniejszyło (odpowiednio 43× i 12×) szybkość rozszczepienia nadkrytycznego plazmidu, wskazując również na znaczenie tych nukleotydów w rozpoznawaniu Blat Cas9 PAM.,
aby zidentyfikować docelowe pozycje rozszczepienia DNA białka Blat Cas9, plazmid zawierający region 20 bp pasujący do odstępu T1, a następnie sekwencję PAM, GTCCCGAA, wchodzącą w zakres konsensusu Pam dla Blat Cas9, nnnncndd, został wygenerowany i strawiony kompleksem rybonukleoprotein RNA-guide Blat Cas9. Bezpośrednie sekwencjonowanie DNA zostało wykorzystane do określenia końców liniowej cząsteczki DNA generowanej przez kompleks Blat Cas9 RNP. Wyniki sekwencji potwierdziły, że rozszczepienie plazmidowego DNA nastąpiło w protospacerze 3 nt 5 ' sekwencji PAM (rys., 4d) podobne do obserwowanych dla białek Spy, Sth3 i Sth1 Cas9 .
w edycji genomu planta przy użyciu Blat Cas9 i sgRNA
po wyjaśnieniu preferencji sgRNA i Pam dla Blat Cas9, zoptymalizowane dla kukurydzy Cas9 i sgRNA kasety ekspresyjne zostały wygenerowane w teście planta, jak wcześniej opisano dla genu S. pyogenes cas9 i sgRNA . Krótko mówiąc, Gen blat cas9 został zoptymalizowany pod kątem kodonu kukurydzy, a intron 2 genu St-LSI ziemniaka został wstawiony w celu zakłócenia ekspresji w E. coli i ułatwienia optymalnego splicingu w planta (dodatkowy plik 1: Rysunek S12)., Lokalizacja jądrowa białka blat Cas9 w komórkach kukurydzy została ułatwiona przez dodanie sygnałów lokalizacji nuklearnych zarówno aminowych, jak i karboksylowo-końcowych, odpowiednio SV40 (MAPKKRKV) i Agrobacterium tumefaciens VirD2 (KRPRDRHDGELGGRKRAR) (dodatkowy plik 1: Rysunek S12). Gen blat cas9 został konstytutywnie wyrażony w komórkach roślinnych poprzez połączenie zoptymalizowanego cas9 z promotorem ubikwityny kukurydzy i terminatorem pinII w wektorze plazmidowego DNA., Aby nadać efektywną ekspresję sgRNA w komórkach kukurydzy, wyizolowano promotor i terminator polimerazy kukurydzy U6 III (ttttttt) i połączono je odpowiednio z końcami 5′ I 3 ' zmodyfikowanej sekwencji DNA Blat sgRNA kodującej sekwencję DNA (dodatkowy plik 1: Rysunek S13). Zmodyfikowany blat sgRNA zawierał dwie zmiany w stosunku do tych stosowanych w badaniach in vitro; zmianę T do G w pozycji 99 i zmianę t do C w pozycji 157 sgRNA (dodatkowy plik 1: Rysunek S13). Zmiany zostały wprowadzone w celu usunięcia potencjalnych przedwczesnych sygnałów zakończenia polimerazy U6 III w blat sgRNA., Zmiany, w przypadku których zostały wprowadzone, miały minimalny wpływ na drugorzędową strukturę sgRNA w porównaniu z wersją stosowaną w badaniach in vitro (dane nie zostały przedstawione).
aby dokładnie porównać efektywność mutacji wynikającą z niedoskonałej naprawy niehomologicznych przerw dwuniciowych DNA (DSBS) wynikającej z rozszczepienia Spy i blat Cas9, wybrano identyczne genomowe miejsca docelowe protospacerów, identyfikując cele z Pam zgodnymi ze Spy i blat Cas9, NGGNCNDD., Identyczne sekwencje dystansowe zostały wybrane dla Blat i Spy Cas9, rejestrując sekwencję 18-21 nt bezpośrednio przed Pam. Aby zapewnić optymalną ekspresję polimerazy U6 III i nie wprowadzić niedopasowania w przestrzeni dystansowej sgRNA, wszystkie sekwencje docelowe zostały wybrane tak, aby naturalnie kończyły się w G na końcu 5′. Cele zostały zidentyfikowane i wybrane w eksonie 1 i 4 genu płodności kukurydzy Ms45 oraz w regionie poprzedzającym Gen Bez liguleless-1 kukurydzy.,
aktywność mutacyjna Blat Cas9 w kukurydzy została zbadana przez biolistycznie przekształcające się 10-dniowe niedojrzałe zarodki kukurydzy (IME) z wektorami DNA zawierającymi geny cas9 i sgRNA. Blat i równoważne Wektory ekspresji Spy Cas9 i sgRNA zostały niezależnie wprowadzone do IME kukurydzy Hi-Type II przez transformację pistoletu cząsteczkowego podobną do opisanej w . Ponieważ transformacja pistoletu cząsteczkowego może być bardzo zmienna, wizualna kaseta ekspresji markera DNA, DS-Red, została również dostarczona wspólnie z wektorami ekspresji Cas9 i sgRNA, aby pomóc w wyborze równomiernie przekształconych IME., Łącznie wykonano trzy replikaty transformacji na 60-90 IME, a 20-30 najbardziej równomiernie przekształconych IME z każdego replikatu zebrano 3 dni po transformacji. Całkowity genomowy DNA ekstrahować i region otaczający cel miejsce amplifikować PCR i amplicons uporządkowywać czytać głębię ponad 300.000. Uzyskane odczyty zostały zbadane pod kątem obecności mutacji w oczekiwanym miejscu rozszczepienia przez porównanie z eksperymentami kontrolnymi, w których kaseta ekspresji dna sgRNA została pominięta podczas transformacji. Jak pokazano na Rys., 5A, mutacje obserwowano w oczekiwanym miejscu rozszczepienia blat Cas9, przy czym najbardziej rozpowszechnionymi typami mutacji były pojedyncze wstawki lub delecje pary zasad. Podobne wzorce naprawy zaobserwowano również dla białka Spy Cas9(dodatkowy plik 1: Rysunek S14 i). Aktywność mutacyjna Blat Cas9 była silna w dwóch z trzech badanych miejsc i przewyższała aktywność szpiegowską Cas9 w miejscu docelowym eksonu 4 Ms45 o około 30% (rys. 5b).
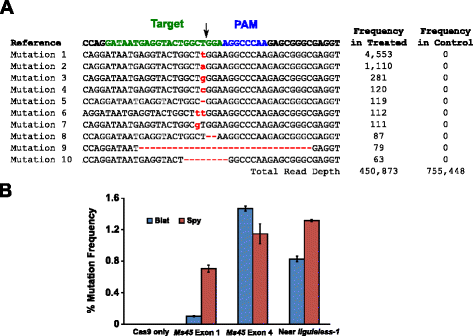
Brevibacillus lateosporus Cas9 Promuje mutacje NHEJ w kukurydzy. 10 najbardziej rozpowszechnionych typów mutacji NHEJ wykrytych z blat Cas9 w eksonie 4 genu Ms45. Czarna strzałka wskazuje oczekiwane miejsce rozszczepienia; mutacje są podświetlone na Czerwono; mała czcionka oznacza wstawienie; ” – ” oznacza usunięcie. b porównanie częstotliwości mutacji Spy i Blat Cas9 Nhej w trzech identycznych protospacerowych miejscach docelowych w kukurydzy. Mutacje NHEJ wykryto przez głębokie sekwencjonowanie 3 dni po transformacji., Pręty błędów reprezentują sem, N = 3 transformacje pistoletu cząsteczkowego. Tylko Cas9 jest kontrolą negatywną i reprezentuje średnią (we wszystkich trzech miejscach docelowych) częstotliwość mutacji w tle wynikającą z amplifikacji i sekwencjonowania PCR