Entwurf und Bau von randomisierten Bibliotheken für untersuchen Cas9 PAM-Einstellungen
die PAM-Bibliotheken mit randomisierten DNA-Sequenzen, die unmittelbar stromabwärts der DNA-Sequenz, die komplementär zu den Abstandshalter, der eine guide RNA generiert und verwendet wurden empirisch zu bestimmen, die PAM-Erkennung vom Typ II Cas9 endonukleasen (Abb. 1)., Bei Fixierung der leitenden RNA-Spacer-Zielsequenz dienen die randomisierten Basen als Substrat für das direkte Auslesen der Cas9-Endonuklease-PAM-Spezifität. Randomisierte Sequenzen wurden in einen Plasmid-DNA-Vektor im PAM-Bereich einer Protospacer-Zielsequenz eingeführt, die eine perfekte Homologie zum leitenden RNA-Spacer T1 (CGCUAAAGAGGAAGAGGACA) demonstriert. Es wurden zwei Bibliotheken generiert, deren Größe und Komplexität von fünf randomisierten Basispaaren (1.024 potenzielle PAM-Kombinationen) auf sieben randomisierte Basispaare (16.384 potenzielle PAM-Kombinationen) anstieg., Die Randomisierung der 5 bp-Bibliothek wurde durch die Synthese eines einzelnen Oligonukleotids mit fünf zufälligen Resten eingeführt. Das einzelsträngige Oligonukleotid wurde durch PCR in eine doppelsträngige Vorlage umgewandelt (Zusätzliche Datei 1: Abbildung S1A), in den Plasmidvektor geklont (zusätzliche Datei 1: Abbildung S1B) und wie im Abschnitt Methoden beschrieben in E. coli umgewandelt., Um eine optimale Zufälligkeit in der 7 bp PAM-Bibliothek zu gewährleisten, wurde die Größe und Komplexität der Bibliothek reduziert, indem vier Oligonukleotide synthetisiert wurden, die jeweils sechs zufällige Rückstände plus einen siebten festen Rückstand enthielten, der G, C, A oder T enthielt. Jedes der vier Oligonukleotide wurde separat in doppelsträngige DNA umgewandelt, wie im Abschnitt Methoden beschrieben in den Vektor pTZ57R/T geklont und wie für die 5 bp-Bibliothek beschrieben in E. coli transformiert., Nach der Transformation wurde Plasmid-DNA gewonnen und aus jeder der vier 6 bp PAM-Bibliotheken kombiniert, um eine randomisierte 7 bp PAM-Bibliothek zu erzeugen, die 16,384 mögliche PAM-Kombinationen umfasst. Für beide Bibliotheken wurde die Einbeziehung der Zufälligkeit durch tiefe Sequenzierung validiert; Untersuchung der Nukleotidzusammensetzung an jeder Position des PAM-Bereichs unter Verwendung einer Positionsfrequenzmatrix (PFM) (Methodenabschnitt und ) (Zusätzliche Datei 1: Abbildung S2A und B)., Die Verteilung und Häufigkeit jeder PAM-Sequenz in der randomisierten PAM-Bibliothek mit 5 bp und 7 bp sind in der zusätzlichen Datei 1 dargestellt: Abbildungen S3 bzw.
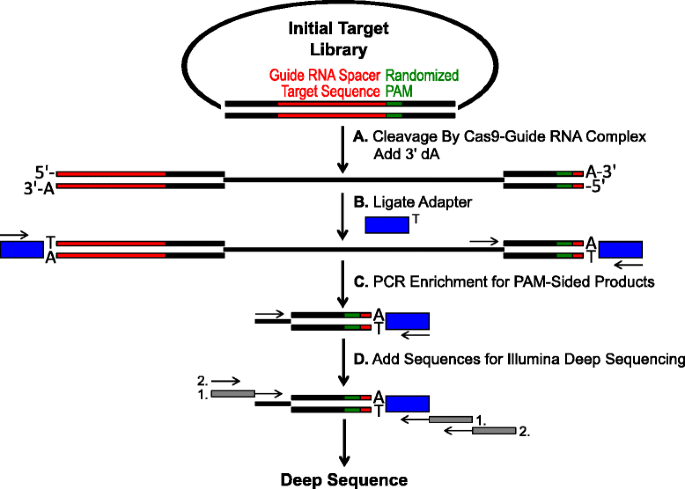
Schema zur Identifizierung von PAM-Präferenzen durch Cas9-Spaltung in vitro. eine anfängliche Plasmidbibliothek mit randomisierter PAM (Green Box) wird mit Cas9 Complex gespalten und 3′ dA Überhänge werden hinzugefügt. b Adapter mit 3 ‚ dT Überhang (blaue Box) sind an beiden Enden des Spaltprodukts ligiert., c-Primer werden verwendet, um für doppelseitig gespaltene Produkte durch PCR anzureichern., d Nach der PCR-Anreicherung werden DNA-Fragmente gereinigt und Illumina-kompatible Anker und Barcodes werden durch zwei Runden PCR (graue Kästchen) und Illumina deep sequenced
Assaying Cas9 PAM Präferenzen
Die im vorherigen Abschnitt beschriebenen randomisierten PAM-Bibliotheken wurden einer In-vitro-Verdauung mit unterschiedlichen Konzentrationen von rekombinantem Cas9-Protein unterzogen, das mit Guide RNA vorinstalliert war.um Cas9-Endonuklease-PAM-Präferenzen dosisabhängig zu testen., Nach der Verdauung mit Cas9-Guide-RNA-Ribonukleoprotein (RNP) – Komplexen wurden PAM-Sequenzkombinationen aus der randomisierten PAM-Bibliothek, die die Spaltung unterstützten, durch ligierende Adapter an den freien Enden der Plasmid-DNA-Moleküle erfasst, die durch den Cas9-Guide-RNA-Komplex gespalten wurden (Abb. 1a und b). Um eine effiziente Ligatur und Erfassung der gespaltenen Enden zu fördern, wurde der stumpfe doppelsträngige DNA-Schnitt, der durch Cas9-Endonukleasen erzeugt wurde, so modifiziert, dass er einen 3′ dA-Überhang enthielt, und die Adapter wurden so modifiziert, dass sie einen komplementären 3′ dT-Überhang enthielten., Um ausreichende Mengen an DNA für die Sequenzierung zu erzeugen, wurden DNA-Fragmente, die die PAM-Sequenz unterstützende Spaltung enthielten, unter Verwendung eines Primers im Adapter und eines anderen direkt angrenzenden PAM-Bereichs PCR amplifiziert (Abb. 1c). Die resultierenden PCR-amplifizierten Cas9-PAM-Bibliotheken wurden in Ampli-seq-Vorlagen umgewandelt (Abb. 1d)und Single-read deep sequenziert von der Adapterseite des Amplicons., Um eine ausreichende Abdeckung zu gewährleisten, wurden die Cas9-PAM-Bibliotheken auf eine Tiefe sequenziert, die mindestens fünfmal größer war als die Vielfalt in der anfänglichen randomisierten PAM-Bibliothek (5.120 und 81.920 Lesevorgänge für die randomisierten 5-und 7-bp-PAM-Bibliotheken). PAM-Sequenzen wurden aus den resultierenden Sequenzdaten identifiziert, indem nur diejenigen Lesevorgänge ausgewählt wurden, die eine perfekte 12-nt-Sequenzübereinstimmung enthalten, die beide Seiten der 5-oder 7-nt-PAM-Sequenz flankiert (abhängig von der verwendeten randomisierten PAM-Bibliothek); Erfassen nur jener PAM-Sequenzen, die sich aus der perfekten Cas9-Guide-RNA-Zielstellenerkennung und-spaltung ergeben., Um inhärente Verzerrungen in den anfänglichen randomisierten PAM-Bibliotheken auszugleichen, wurde die Häufigkeit jeder PAM-Sequenz auf ihre Häufigkeit in der Startbibliothek normalisiert. Da der hier beschriebene Assay direkt Cas9-spaltbare PAM-Sequenzen erfasst, wurde die probabilistische Modellierung verwendet, um den PAM-Konsens für jedes Cas9-Protein zu berechnen. Dies wurde erreicht, indem die Wahrscheinlichkeit, jedes Nukleotid (G, C, A oder T) an jeder Position der PAM-Sequenz unabhängig zu finden, unter Verwendung einer Positionsfrequenzmatrix (PFM) (Methodenabschnitt und) bewertet wurde., Die resultierenden Wahrscheinlichkeiten wurden dann als WebLogo visualisiert .
Um die Neigung zu Fehlalarmen im Assay zu untersuchen, wurde auf die Zugabe von Cas9 RNP-Komplexen im Verdauungsschritt verzichtet (Abb. 1a) und der Assay wurde durch den PCR-Anreicherungsschritt durchgeführt (Abb. 1c). Wie in der zusätzlichen Datei 1: Abbildung S5A gezeigt, wurden in Abwesenheit von Cas9-leitenden RNA-Komplexen keine Amplifikationsprodukte nachgewiesen. Dies zeigt an, dass die Inzidenz von Fehlalarmen gering ist und nicht signifikant zu den Ergebnissen des Assays beiträgt.,
PAM-Präferenzen von Streptococcus pyogenes und Streptococcus thermophilus (CRISPR3-und CRISPR1-Systeme) Cas9-Proteinen
Zur Validierung des Assays wurden die PAM-Präferenzen von Streptococcus pyogenes (Spy) und Streptococcus thermophilus CRISPR3 (Sth3) Cas9-Proteinen untersucht, über deren PAM-Sequenzbedarf zuvor berichtet wurde. In vitro-Digests wurden mit 1 µg (5,6 nM) der randomisierten PAM-Bibliothek von 5 bp in zwei Konzentrationen, 0,5 und 50 nM, von vormontierten Spy-oder Sth3-Cas9-Protein -, crRNA-und tracrRNA-RNP-Komplexen für 1 h in einem Reaktionsvolumen von 100 µL durchgeführt., Basierend auf ihrer Häufigkeit in der randomisierten 5-bp-PAM-Bibliothek lagen Spy-und Sth3-Cas9-PAM-Sequenzen (NGG bzw. NGGNG) bei Endkonzentrationen von 0,40 nM bzw. Mitglieder der randomisierten PAM-Bibliothek, die PAM-Sequenzen enthielten, die die Spaltung unterstützten, wurden wie im vorherigen Abschnitt beschrieben erfasst und identifiziert. Als Negativkontrolle wurde die anfängliche nicht geteilte randomisierte PAM-Bibliothek neben den Bibliotheken, die Cas9-RNP-Komplexen ausgesetzt waren, einer Sequenzierung und PFM-Analyse unterzogen., Wie in der zusätzlichen Datei 1: Abbildung S5B und C gezeigt, existieren keine Sequenzpräferenzen in Abwesenheit eines Cas9 RNP-Komplexes, wie durch eine nahezu perfekte Verteilung jedes Nukleotids an jeder Position der PAM in der PFM-Tabelle und den Mangel an informativen Inhalten im WebLogo für die Kontrolle deutlich wird. Dies ist in stark constrast mit Fig. 2a und b, die die Zusammensetzung der Sequenzen veranschaulicht, die aus Bibliotheken stammen, die mit Spy-und Sth3-Cas9-RNP-Komplexen verdaut wurden. Untersuchung des PFM abgeleiteten WebLogos (Abb., 2a und b) zeigen auch das Vorhandensein der kanonischen PAM-Präferenzen für die Spion-und Sth3-Cas9-Proteine NGG bzw. NGGNG. Obwohl die PAM-Präferenzen für Spy-und Sth3-Cas9-Proteine sowohl in den 0,5 nM-als auch in 50 nM-Digests beobachtet werden, gibt es eine allgemeine Erweiterung der Spezifität unter den 50 nM-Digestbedingungen. Dies ist am deutlichsten an Position 2 für das Spion-Cas9-Protein, wo die Häufigkeit eines nicht-kanonischen A-Rückstands dramatisch zunimmt (Abb. 2a)., For Sth3, all PAM positions exhibit a marked decrease in specificity as a result of increasing the RNP complex concentration (Fig. 2b).
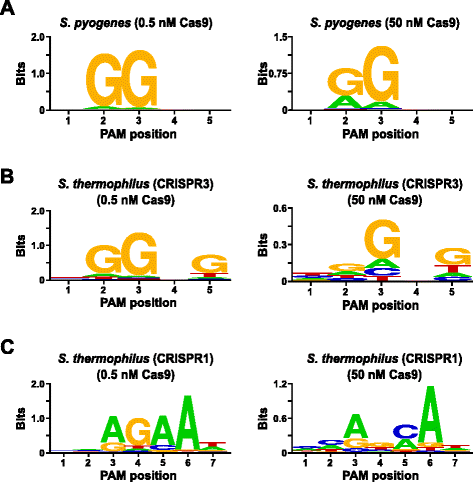
PAM preferences for S. pyogenes (a), S. thermophilus CRISPR3 (b), and S. thermophilus CRISPR1 (c) Cas9 proteins., Die Häufigkeit von Nukleotiden an jeder PAM-Position wurde unabhängig unter Verwendung einer Positionsfrequenzmatrix (PFM) berechnet und als WebLogo
Eine weitere Validierung des Assays wurde durch Untersuchung der PAM-Präferenzen für das Streptococcus thermophilus CRISPR1 (Sth1) Cas9-Protein durchgeführt, dessen PAM-Spezifität sich auf 7 bp erstreckt . Unter Verwendung von 1 µg (5,6 nM) der randomisierten 7-bp-PAM-Bibliothek als Vorlage wurden Sth1-Cas9-Guide-RNA-Digestionen in zwei Konzentrationen, 0,5 nM und 50 nM, des RNP-Komplexes durchgeführt, wie oben beschrieben., Als Kontrollen wurden Spy – und Sth3-Cas9-RNP-Komplexe auch verwendet, um die randomisierte PAM-Bibliothek mit 7 bp zu verdauen, jedoch nur bei einer RNP-Komplexkonzentration von 0,5 nM. Basierend auf der Frequenz in der randomisierten 7-bp-PAM-Bibliothek lagen die zuvor für Sth1 (NNAGAAW), Spy (NGG) und Sth3 (NGGNG) gemeldeten PAM-Sequenzen bei Endkonzentrationen von 0,01 nM, 0,22 nM bzw., Wie in zusätzlicher Datei 1: Abbildung S6A und B gezeigt, waren die PAM-Präferenzen für Spy-und Sth3-Cas9-Proteine, die mit der 7-BP-Bibliothek erzeugt wurden, nahezu identisch mit denen, die mit der 5-BP-Bibliothek erzeugt wurden, was einen starken Beweis für die Reproduzierbarkeit des Assays lieferte. Die PAM-Präferenzen für das Sth1-Cas9-Protein stimmten auch eng mit der zuvor berichteten NNAGAAW bei der 0,5 nM Cas9-leitenden RNA-Komplexkonzentration überein (Abb. 2c)., Ähnlich wie Spy-und Sth3-Cas9-Proteine war Sth1-Cas9 in der Lage, einen vielfältigeren Satz von PAM-Sequenzen in den Reaktionen zu spalten, die eine höhere Konzentration von Cas9-leitendem RNA-Komplex (50 nM) enthielten, am auffälligsten war der deutliche Verlust des G-Rückstands an Position 4 und die nahezu gleiche Präferenz für ein C und ein bp an Position 5 (Abb. 2c). Dies führte zu einem anderen PAM-Konsens als dem, der bei niedrigeren Konzentrationen erhalten wurde.,
Um zu untersuchen, ob die PAM-Spezifität unabhängig von der Art der leitenden RNA ist , wurden Duplex-crRNA:tracrRNA oder sgRNA, Spy -, Sth3-und Sth1-Cas9-PAM-Präferenzen ebenfalls unter Verwendung eines binären Cas9-und sgRNA-RNP-Komplexes untersucht. Die Verdauung wurde bei einer einzigen RNP-Komplexkonzentration von 0,5 nM durchgeführt und die PAM-Präferenzanalyse wurde wie oben beschrieben durchgeführt. Wie in der zusätzlichen Datei 1: Abbildung S7A, B und C gezeigt, waren die PAM-Präferenzen nahezu identisch, unabhängig von der Art der verwendeten Guide-RNA; entweder eine crRNA:tracrRNA Duplex oder sgRNA., Um zu bestätigen, dass die Spezifität der PAM nicht stark von der Zusammensetzung der Ziel-DNA oder Spacer-Sequenz beeinflusst wird, wurde die Sequenz auf der gegenüberliegenden Seite der randomisierten 5-oder 7-bp-Bibliothek auf die Spaltung mit einem anderen Spacer ausgerichtet; T2-5 (UCUAGAUAGAUUACGAAUUC) für die 5-BP-Bibliothek oder T2-7 (CCGGCGACGUUGGGUCAACU) für die 7-BP-Bibliothek. Spy-und Sth3-Cas9-Proteine, die mit sgRNAs vorinstalliert waren, die auf die T2-Sequenz abzielten, wurden verwendet, um die randomisierte 5-BP-PAM-Bibliothek abzufragen, während die Sth1-Cas9-T2-sgRNA-Komplexe verwendet wurden, um die randomisierte 7-BP-PAM-Bibliothek zu verdauen., PAM-Präferenzen wurden wie oben beschrieben getestet. Die PAM-Präferenzen für alle 3 Cas9-Proteine waren unabhängig von Spacer-und Ziel-DNA-Sequenz nahezu identisch (Zusätzliche Datei 1: Abbildung S8A, B und C).
Identifizierung von sgRNA-und PAM-Präferenzen für das Brevibacillus laterosporus Cas9-Protein
Um die PAM-Präferenzen für ein Cas9-Protein, dessen PAM nicht definiert war, empirisch zu untersuchen, wurde ein uncharakterisierter CRISPR-Cas-Locus vom Typ II-C aus Brevibacillus Laterosporus-Stamm SSP360D4 (Blat) identifiziert, indem interne DuPont Pioneer-Datenbanken nach Cas9-Orthologen durchsucht wurden., 4,5 kb) enthielt ein cas9-Gen, das in der Lage war, ein 1,092-Polypeptid zu codieren, ein CRISPR-Array, das sieben Repeat-Spacer-Einheiten direkt stromabwärts des cas9-Gens und einen tracrRNA-codierenden Bereich stromaufwärts des cas9-Gens mit partieller Homologie zum CRISPR-Array umfasst Wiederholungen (Abb. 3a). Die Wiederholungs – und Distanzlänge (entsprechend 36 und 30 bp) ähnelt anderen CRISPR-Cas-Systemen vom Typ II mit fünf der acht Wiederholungen, die 1 oder 2 bp-Mutationen enthalten (Abb. 3b und Zusätzliche Datei 1: Abbildung S9)., Andere Gene, die typischerweise in einem CRISPR-Cas-Locus vom Typ II gefunden wurden, waren entweder abgeschnitten (cas1) oder fehlten (Abb. 3a).
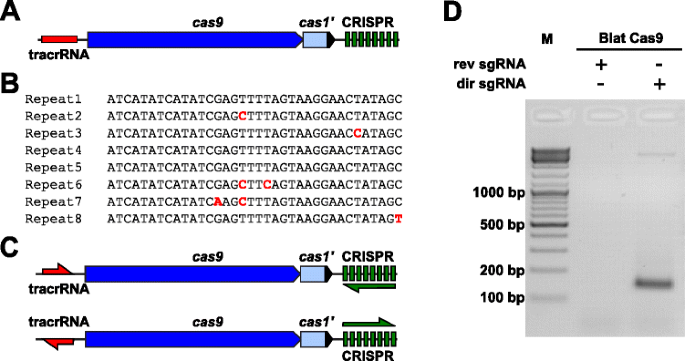
Identifizierung von CRISPR-Cas-Elementen vom Typ II im Brevibacillus laterosporus SSP360D4 CRISPR-Cas-System. a Eine Illustration der genomischen DNA-Region aus dem Typ II CRISPR-Cas-System von Brevibacillus laterosporus SSP360D4. b Vergleich von CRISPR-Array-Wiederholungssequenzen vom Typ II, die in Brevibacillus laterosporus SSP360D4 identifiziert wurden., c Die „direkten“ und „umgekehrten“ tracrRNA-und CRISPR-Array-Transkriptionsszenarien für das CRISPR-Cas-System Typ II von Brevibacillus laterosporus SSP360D4. d Ein Agarosegel mit Reaktionsprodukten, das anzeigt, dass nur die“direkte“sgRNA (dir sgRNA), nicht aber die „umgekehrte“ sgRNA (rev sgRNA) die Spaltung der Plasmidbibliothek in Kombination mit der Cas9-Endonuklease unterstützt, die von Brevibacillus laterosporus SSP360D4 stammt
Die Leitungs-RNA-Anforderung für die Blat Cas9-Endonuklease protein wurde durch Erzeugung von zwei sgRNA-Varianten bestimmt., Diese Varianten wurden generiert, um sowohl mögliche Sense – als auch Anti-Sense-Expressionsszenarien des tracrRNA-und CRISPR-Arrays zu berücksichtigen (Abb. 3c) und verwendet, um zu untersuchen, welches Expressszenario die Spaltaktivität von Blat Cas9 in der randomisierten PAM-Bibliothek unterstützte. Single Guide RNAs wurden entwickelt, indem zunächst die Grenzen der mutmaßlichen tracrRNA-Moleküle durch Analyse von Regionen identifiziert wurden, die teilweise komplementär zum 22 nt 5′ – Terminus der Wiederholung waren (Anti-Wiederholung)., Als nächstes, um das 3′ Ende der tracrRNA zu bestimmen, wurden mögliche Sekundärstrukturen und Terminatoren verwendet, um den Bereich der Beendigung in dem nachgeschalteten Fragment vorherzusagen. Dies wurde durch Screening auf das Vorhandensein von Rho-ähnlichen Terminierungssequenzen in der DNA erreicht, die das Anti-Repeat umgeben, ähnlich dem in Karvelis et al. , umwandlung der umgebenden DNA in RNA-Sequenz und Untersuchung der resultierenden Strukturen mit UNAfold ., Die resultierenden sgRNAs wurden entworfen, um ein T7-Polymerase-Transkriptionsinitiationserkennungssignal am 5′ – Ende zu enthalten, gefolgt von einer 20 nt-Zielerkennungssequenz, 16 nt crRNA-Wiederholung, 4 nt selbstfaltender Haarnadelschleife und Anti-Wiederholungssequenz komplementär zum Wiederholungsbereich der crRNA, gefolgt von dem verbleibenden 3′ – Teil der mutmaßlichen TRACRNA. Die sgRNA-Variante, die eine mutmaßliche tracrRNA enthält, die in die gleiche Richtung wie das cas9-Gen transkribiert wurde (Abb. 3c) wird als „direkte“ sgRNA bezeichnet, während die sgRNA, die die tracrRNA enthält, in die entgegengesetzte Richtung eine „umgekehrte“ sgRNA transkribiert., Fünfzig nM Blat Cas9 sgRNA RNP-Komplex, der entweder mit den „direkten“ oder „umgekehrten“ sgRNAs vorinstalliert war, wurden mit 1 µg (5,6 nM) der 7 bp randomisierten PAM-Bibliothek inkubiert. Nach Bibliotheksverdau und Zugabe von 3 ‚ dA-Überhängen wurden Adapter ligiert und Spaltprodukte PCR-amplifiziert (Abb. 1). Die Analyse von Reaktionsprodukten durch Agarosegelelektrophorese ergab, dass die „direkte“ sgRNA, nicht aber die „umgekehrte“ sgRNA die Spaltung der Plasmidbibliothek unterstützte (Abb. dreidimensional). Die Reihenfolge und die vorhergesagte Sekundärstruktur der ‚direkten‘ sgRNA sind in zusätzlicher Datei 1 dargestellt: Abbildung S10.,
Nach Bestimmung der geeigneten leitenden RNA für Blat Cas9 wurde die PAM-Identifizierung ähnlich der oben beschriebenen für die Spy -, Sth3-und Sth1-Cas9-Proteine gegen die randomisierte 7-bp-PAM-Bibliothek mit zwei Konzentrationen (0,5 und 50 nM) des vormontierten Blat Cas9-Direkt-sgRNA-RNP-Komplexes durchgeführt. Wie in Abb. 4a war der PFM-WebLogo-PAM-Konsens für das Blat-Cas9-Protein unter den 0,5 nM-Verdauungsbedingungen NNNNCND (N = G, C, A oder T; D = A, G oder T) mit einer starken Präferenz für ein C an Position 5 der PAM-Sequenz., Eine moderate Präferenz für ein A wurde an Position 7 beobachtet und leichte Präferenzen für ein C oder T an Position 4 und G, C oder A gegenüber T an Position 6 wurden ebenfalls bei genauer Untersuchung der PFM-Tabelle festgestellt (zusätzliche Datei 1: Abbildung S11). Ähnlich wie Spy -, Sth3-und Sth1-Cas9-Proteine erweitert sich die PAM-Spezifität, wenn die Cas9-sgRNA-Komplexkonzentration zunimmt. Dies ist am deutlichsten an Position 5, wo ein größerer Anteil von PAM-Sequenzen, die einen A-Rückstand enthalten, eine Spaltung bei 50 nM im Vergleich zu den 0,5 nM-Verdauungsbedingungen unterstützt.
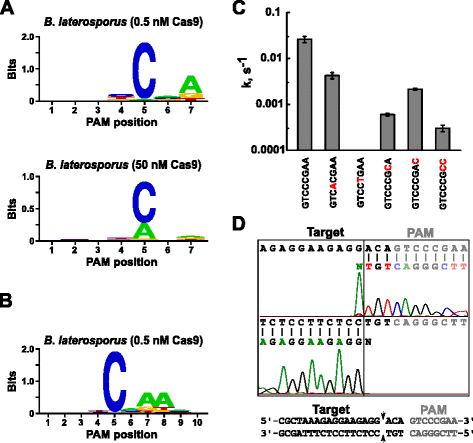
PAM Vorlieben und Dekolleté Positionen Brevibacillus laterosporus SSP360D4 (Blat) Cas9-Enzym. Blat Cas9 PAM-Präferenzen, wenn 1 µg Bibliotheks-DNA mit 0,5 nM oder 50 nM Cas9-sgRNA-Komplex (a) gespalten wurde, dehnten sich auf Position 10 aus, indem das Protospacer-Ziel um 3 bp (b) verschoben wurde. Die Frequenz der Nukleotide an jeder PAM-Position wurde unabhängig unter Verwendung einer Positionsfrequenzmatrix (PFM) berechnet und als WebLogo aufgetragen ., c Spaltungsraten von supercoiled Plasmid-DNA-Substraten mit Mutationen (rot dargestellt) in GTCCCGAA PAM-Sequenz. Alle Datenpunkte sind Mittelwerte aus ≥3 unabhängigen Experimenten. Fehlerbalken werden als S. D. d-Run-Off-Sequenzierung aus Sense-und Anti-Sense-Richtungen von Plasmid-DNA angegeben, die mit Blat Cas9
Da Blat Cas9 möglicherweise eine beliebige Basis in den ersten drei Positionen seiner PAM-Sequenz akzeptiert (Abb. 4a) wurde der Spacer T1 um drei Nukleotide in 5′ – Richtung verschoben, um eine Ausdehnung der PAM-Identifizierung von 7 auf 10 bp zu ermöglichen., Der verschobene T1-Spacer T1-3 (AAACGCUAAAGAGGAAGAGG) wurde in die direkte sgRNA von Blat integriert, und die PAM-Identifizierung wurde wie zuvor für Spy -, Sth3 -, Sth1-und Blat-Cas9-Proteine beschrieben durchgeführt. Die PAM-Präferenzanalyse ergab, dass die PAM-Spezifität für Blat Cas9 auf Position 8 ausgedehnt werden kann, wo eine moderate Präferenz für ein zusätzliches A besteht (Abb. 4b).
Die PAM-Spezifität für Blat Cas9 wurde durch die Erzeugung von Plasmiden bestätigt, die Mutationen in den am meisten konservierten Resten der PAM enthalten (Abb. 4c)., Durch den Ersatz des C-Nukleotids an Position 5 wurde die Plasmid-DNA-Spaltung abgeschafft, was seine Schlüsselrolle bei der Blat-Cas9-PAM-Erkennung bestätigt. Ersatz eines Nukleotides an den Positionen 7 und 8 signifikant reduziert (43× und 12×, beziehungsweise) die Spaltungsrate von supercoiled Plasmid zeigt auch die Bedeutung dieser Nukleotide in Blat Cas9 PAM Anerkennung.,
Um die DNA-Zielspaltungspositionen für das Blat Cas9-Protein zu identifizieren, wurde ein Plasmid, das eine 20 bp-Region enthält, die mit dem Spacer T1 übereinstimmt, gefolgt von einer PAM-Sequenz, GTCCCGAA, die in den PAM-Konsens für Blat Cas9, NNNNCNDD, fällt, erzeugt und mit dem Blat Cas9-Guide-RNA-Ribonukleoproteinkomplex verdaut. Die direkte DNA-Sequenzierung wurde verwendet, um die Enden des linearen DNA-Moleküls zu bestimmen, das vom Blat Cas9 RNP-Komplex erzeugt wurde. Die Sequenzergebnisse bestätigten, dass eine Plasmid-DNA-Spaltung im Protospacer 3 nt 5′ der PAM-Sequenz auftrat (Abb., 4d) ähnlich wie bei Spy -, Sth3-und Sth1-Cas9-Proteinen.
In planta Genom-Bearbeitung mit Blat Cas9 und sgRNA
Folgende Aufklärung der sgRNA und PAM-Einstellungen für Blat Cas9, mais optimiert Cas9-und sgRNA-expression Kassetten generiert wurden, in planta-Tests, wie zuvor beschrieben, die für die S. pyogenes cas9 gen-und sgRNA . Kurz gesagt, das Blat cas9-Gen wurde Mais-Codon optimiert und Intron 2 des Kartoffel-ST-LSI-Gens wurde eingefügt, um die Expression in E. coli zu stören und das optimale Spleißen in Planta zu erleichtern (Zusätzliche Datei 1: Abbildung S12)., Die nukleare Lokalisation des Blat Cas9-Proteins in Maiszellen wurde durch die Zugabe von amino-und carboxyl-terminalen nuklearen Lokalisierungssignalen SV40 (MAPKKKRKV) bzw. Agrobacterium tumefaciens VirD2 (KRPRDRHDGELGGRKRAR) erleichtert (Zusätzliche Datei 1: Abbildung S12). Das Blat cas9-Gen wurde konstitutiv in Pflanzenzellen exprimiert, indem das optimierte cas9 mit einem Mais-Ubiquitin-Promotor und einem pinII-Terminator in einem Plasmid-DNA-Vektor verknüpft wurde., Um eine effiziente sgRNA-Expression in Maiszellen zu gewährleisten, wurden ein Mais-U6-Polymerase-III-Promotor und ein Terminator (TTTTTTTT) isoliert und an den 5′ – und 3′ – Enden einer modifizierten Blat-sgRNA-kodierenden DNA-Sequenz verschmolzen (Zusätzliche Datei 1: Abbildung S13). Die modifizierte Blat-sgRNA enthielt zwei Modifikationen von denen, die in den In-vitro-Studien verwendet wurden; eine T-zu-G-Veränderung an Position 99 und eine T-zu-C-Modifikation an Position 157 der sgRNA (zusätzliche Datei 1: Abbildung S13). Die Änderungen wurden eingeführt, um potenzielle vorzeitige U6-Polymerase-III-Terminierungssignale in der Blat sgRNA zu entfernen., Änderungen wurden eingeführt, um einen minimalen Einfluss auf die Sekundärstruktur der sgRNA im Vergleich zu der in den In-vitro-Studien verwendeten Version zu haben (Daten nicht gezeigt).
Um die Mutationseffizienz, die sich aus der unvollkommenen nicht-homologen Endverbindungsreparatur (NHEJ) von DNA-Doppelstrangbrüchen (DSBs) ergibt, die sich aus Spy-und Blat-Cas9-Spaltung ergibt, genau zu vergleichen, wurden Protospacer-identische genomische Zielstellen ausgewählt, indem Ziele mit Spy-und Blat-Cas9-kompatiblen PAMs, NGGNCNDD, identifiziert wurden., Identische Distanzsequenzen wurden für Blat und Spy Cas9 ausgewählt, indem die 18-bis 21-nt-Sequenz unmittelbar vor der PAM erfasst wurde. Um eine optimale U6-Polymerase-III-Expression zu gewährleisten und keine Fehlanpassung innerhalb des sgRNA-Spacers einzuführen, wurden alle Zielsequenzen ausgewählt, um natürlich in einem G an ihrem 5′ – Ende zu enden. Ziele wurden identifiziert und ausgewählt in exon 1 und 4 der mais die Fruchtbarkeit gen Ms45 und in einer region oberhalb der mais liguleless-1-Gens.,
Die Mutationsaktivität von Blat Cas9 in Mais wurde durch biolistisch transformierende 10 Tage alte unreife Maisembryonen (IMEs) mit DNA-Vektoren untersucht, die cas9-und sgRNA-Gene enthielten. Blat und die äquivalenten Spion Cas9-und sgRNA-Expressionsvektoren wurden unabhängig voneinander in Mais Hi-Typ II IME durch Partikelpistolentransformation ähnlich der in beschrieben eingeführt . Da die Partikelzelltransformation sehr variabel sein kann, wurde auch eine visuelle Marker-DNA-Expressionskassette, Ds-Red, zusammen mit den Cas9-und sgRNA-Expressionsvektoren geliefert, um die Auswahl gleichmäßig transformierter IME zu unterstützen., Insgesamt wurden drei Transformationsreplikate an 60-90 IME durchgeführt und 20-30 der gleichmäßigsten transformierten IME aus jedem Replikat wurden 3 Tage nach der Transformation geerntet. Die gesamte genomische DNA wurde extrahiert und die Region um die Zielstelle herum wurde durch PCR amplifiziert und Amplicons auf eine Lesetiefe von mehr als 300.000 sequenziert. Die resultierenden Lesevorgänge wurden auf das Vorhandensein von Mutationen an der erwarteten Spaltstelle im Vergleich zu Kontrollexperimenten untersucht, bei denen die sgRNA-DNA-Expressionskassette von der Transformation weggelassen wurde. Wie in Abb., 5a wurden Mutationen an der erwarteten Spaltstelle für Blat Cas9 beobachtet, wobei die am häufigsten vorkommenden Arten von Mutationen einzelne Basenpaareinfügungen oder Deletionen waren. Ähnliche Reparaturmuster wurden auch für das Spy Cas9 Protein beobachtet (Zusätzliche Datei 1: Abbildung S14 und ). Die Mutationsaktivität für Blat Cas9 war an zwei der drei getesteten Stellen robust und übertraf die des Spy Cas9 an der Ms45 exon 4-Zielstelle um etwa 30 % (Abb. 5b).
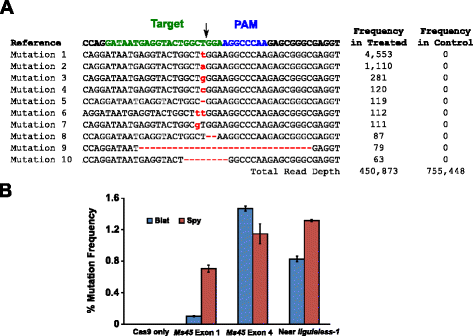
Brevibacillus laterosporus Cas9 fördert NHEJ Mutationen in mais. eine Top 10 der am häufigsten vorkommenden Arten von NHEJ-Mutationen, die mit Blat Cas9 in Exon 4 des Ms45-Gens nachgewiesen wurden. Ein schwarzer Pfeil zeigt die erwartete Stelle der Spaltung an; Mutationen sind rot hervorgehoben; Kleinbuchstaben zeigen eine Einfügung an; ‚ – ‚ zeigt eine Löschung an. b Vergleich der Spy-und Blat Cas9 NHEJ-Mutationsfrequenzen an drei Protospacer-identischen Zielstellen in Mais. NHEJ-Mutationen wurden 3 Tage nach der Transformation durch tiefe Sequenzierung nachgewiesen., Fehlerbalken repräsentieren SEM, n = 3 Teilchen-gun-Transformationen. Cas9 ist nur die negative Kontrolle und stellt die durchschnittliche (über alle drei Zielstellen hinweg) Hintergrundfrequenz von Mutationen dar, die sich aus PCR-Verstärkung und-Sequenzierung ergeben