Betrachten Sie einen Fall, in dem Sie Features erstellt haben, Sie wissen um die Bedeutung von Features und Sie sollen ein Klassifizierungsmodell erstellen, das in sehr kurzer Zeit präsentiert werden soll?
Was werden Sie tun? Sie haben eine sehr große Menge an Datenpunkten und sehr wenige Funktionen in Ihrem Datensatz., In dieser Situation hätte ich, wenn ich ein solches Modell erstellen müsste, „Naive Bayes“ verwendet, was als ein wirklich schneller Algorithmus für Klassifizierungsaufgaben angesehen wird.
In diesem Blog versuche ich zu erklären, wie der Algorithmus funktioniert, der in solchen Szenarien verwendet werden kann. Wenn Sie wissen möchten, was Klassifizierung und andere solche Algorithmen ist, können Sie hier verweisen.
Naive Bayes ist ein Modell für maschinelles Lernen, das für große Datenmengen verwendet wird, auch wenn Sie mit Daten arbeiten, die Millionen von Datensätzen enthalten Der empfohlene Ansatz ist Naive Bayes., Es gibt sehr gute Ergebnisse, wenn es um NLP-Aufgaben wie sentimentale Analyse geht. Es ist ein schneller und unkomplizierter Klassifizierungsalgorithmus.
Um den naiven Bayes-Klassifikator zu verstehen, müssen wir den Bayes-Satz verstehen. Lassen Sie uns also zuerst den Bayes-Satz diskutieren.
Bayes Theorem
Es ist ein Satz, der auf bedingte Wahrscheinlichkeit arbeitet. Bedingte Wahrscheinlichkeit ist die Wahrscheinlichkeit, dass etwas passiert, da bereits etwas anderes aufgetreten ist. Die bedingte Wahrscheinlichkeit kann uns die Wahrscheinlichkeit eines Ereignisses mit seinem Vorwissen geben.,
Bedingte Wahrscheinlichkeit:
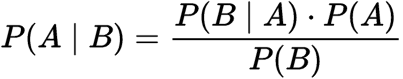
Bedingte Wahrscheinlichkeit
Wobei
P(A): Die Wahrscheinlichkeit, dass Hypothese H wahr ist. Dies wird als vorherige Wahrscheinlichkeit bezeichnet.
P(B): Die Wahrscheinlichkeit der Beweise.
P(A|B): Die Wahrscheinlichkeit, der Beweis, dass die Hypothese wahr ist.
P (B|A): Die Wahrscheinlichkeit der Hypothese, dass die Beweise wahr sind.
Naive Bayes Klassifikator
-
Es ist eine Art Klassifikator, der auf Bayes Theorem arbeitet.,
-
Die Vorhersage der Mitgliedschaftswahrscheinlichkeiten wird für jede Klasse vorgenommen, z. B. für die Wahrscheinlichkeit von Datenpunkten, die einer bestimmten Klasse zugeordnet sind.
-
Die Klasse mit maximaler Wahrscheinlichkeit wird als die am besten geeignete Klasse bewertet.
- Dies wird auch bezeichnet als Maximum A Posteriori (MAP).
-
NB-Klassifikatoren schließen daraus, dass alle Variablen oder Merkmale nicht miteinander verwandt sind.
-
Das Vorhandensein oder Fehlen einer Variablen hat keinen Einfluss auf das Vorhandensein oder Fehlen einer anderen Variablen.,
-
Beispiel:
-
Frucht kann beobachtet werden, dass ein Apfel ist, wenn er rot, rund und etwa 4″ im Durchmesser ist.
-
In diesem Fall auch dann, wenn alle Merkmale miteinander verbunden sind, und der Klassifikator beobachtet alle diese unabhängig voneinander, was zur Wahrscheinlichkeit beiträgt, dass die Frucht ein Apfel ist.
-
-
Wir experimentieren mit der Hypothese in realen Datensätzen bei mehreren Merkmalen.
-
Die Berechnung wird also komplex.
Typen Naiver Bayes-Algorithmen
1., Gaußsche Naive Bayes: Wenn charakteristische Werte kontinuierlicher Natur sind, wird davon ausgegangen, dass die mit jeder Klasse verknüpften Werte gemäß Gaußscher Normalverteilung verteilt sind.
2. Multinomial Naive Bayes: Multinomial Naive Bayes wird bevorzugt, um Daten zu verwenden, die multinomial verteilt sind. Es ist weit verbreitet in der Textklassifizierung in NLP. Jedes Ereignis in der Textklassifizierung stellt das Vorhandensein eines Wortes in einem Dokument dar.
3., Bernoulli Naive Bayes: Wenn Daten gemäß den multivariaten Bernoulli-Verteilungen ausgegeben werden, wird Bernoulli Naive Bayes verwendet. Das bedeutet, dass es mehrere Funktionen gibt, von denen jedoch angenommen wird, dass sie einen Binärwert enthalten. Daher müssen Funktionen binär bewertet werden.
Vor-und Nachteile von Naive Bayes
Vorteile:
-
Es ist ein sehr erweiterbarer Algorithmus, der sehr schnell ist.
-
Es kann sowohl für Binärdateien als auch für die Klassifizierung mehrerer Klassen verwendet werden.,
-
Es hat hauptsächlich drei verschiedene Arten von algorithmen, die GaussianNB, MultinomialNB, BernoulliNB.
-
Es ist ein berühmter Algorithmus für Spam-E-Mail-Klassifizierung.
-
Es kann leicht auf kleinen Datensätzen trainiert werden und kann auch für große Datenmengen verwendet werden.
Nachteile:
-
Der Hauptnachteil des NB besteht darin, alle Variablen unabhängig zu betrachten, was zur Wahrscheinlichkeit beiträgt.,
Anwendungen naiver Bayes-Algorithmen
-
Echtzeit-Vorhersage: Ein schneller Lernalgorithmus kann auch verwendet werden, um Vorhersagen in Echtzeit zu treffen.
-
Multiklassenklassifizierung: Es kann auch für Mehrklassenklassifizierungsprobleme verwendet werden.
-
Textklassifizierung: Da es gute Ergebnisse bei der Vorhersage der Klassifizierung mehrerer Klassen gezeigt hat, weist es im Vergleich zu allen anderen Algorithmen mehr Erfolgsraten auf. Infolgedessen wird es hauptsächlich in der Stimmungsanalyse & Spam-Erkennung verwendet.,
Praktische Problemanweisung
Die Problemanweisung besteht darin, Patienten als Diabetiker oder Nichtdiabetiker zu klassifizieren. Der Datensatz kann von der Kaggle-Website „PIMA INDIAN DIABETES DATABASE“ heruntergeladen werden. Die Datensätze hatten verschiedene medizinische Prädiktormerkmale und ein Ziel, das „Ergebnis“ ist. Zu den Prädiktorvariablen gehören die Anzahl der Schwangerschaften, die der Patient hatte, sein BMI, sein Insulinspiegel, sein Alter usw.,
Codimplementierung zum Importieren und Aufteilen der Daten
STEPS-
- Zunächst werden alle erforderlichen Bibliotheken wie numpy, pandas, train-test_split, GaussianNB, metrics importiert.
- Da es sich um eine Datendatei ohne Header handelt, geben wir die Spaltennamen an, die von der obigen URL erhalten wurden
- Hat eine Python-Liste mit Spaltennamen namens „Namen“erstellt.
- Initialisierte Prädiktorvariablen und das Ziel, das X bzw.
- Transformierte die Daten mit StandardScaler.,
- Teilen Sie die Daten in Trainings-und Testsätze auf.
- Erstellt ein Objekt für GaussianNB.
- Passen Sie die Daten im Modell an, um sie zu trainieren.
- Machte Vorhersagen für den Testsatz und speicherte ihn in einer ‚predictor‘ – Variablen.
Für die explorative Datenanalyse des Datensatzes können Sie nach den Techniken suchen.

Verwirrung-matrix & Modell-score-test data
- Importiert accuracy_score und confusion_matrix from sklearn.Metrik., Gedruckt die Verwirrungsmatrix zwischen vorhergesagt und tatsächlich, die uns die tatsächliche Leistung des Modells sagt.
- Berechnete den model_score der Testdaten, um zu wissen, wie gut das Modell bei der Verallgemeinerung der beiden Klassen funktioniert, die sich als 74% herausstellten.,
model_score = model.score(X_test, y_test)model_score

Auswertung des Modells

Roc_score
- Importiert auc, roc_curve wieder von sklearn.Metrik.
- Gedruckte roc_auc Punktzahl zwischen falsch-positiven und positiver wahr, dass kam heraus, dass 79%.
- Importierte matplotlib.pyplot-Bibliothek zum Zeichnen des roc_curve.
- Druckte die roc_curve.,
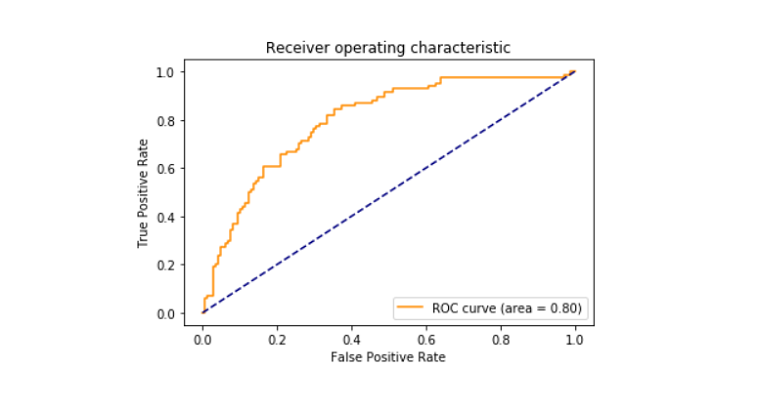
Roc_curve
Die auch als roc_curve bezeichnete Empfängerbetriebskennlinie ist ein Diagramm, das das Interpretationspotential eines binären Klassifikatorsystems beschreibt. Es wird zwischen der wahren positiven Rate und der falsch positiven Rate an verschiedenen Schwellenwerten aufgetragen. Die ROC-Kurve Gebiet gefunden wurde, 0.80.
Für die Python-Datei und auch das verwendete Dataset im obigen Problem können Sie hier auf den Github-Link verweisen, der beide enthält.,
Schlussfolgerung
In diesem Blog habe ich naive Bayes-Algorithmen diskutiert, die für Klassifizierungsaufgaben in verschiedenen Kontexten verwendet werden. Ich habe die Rolle des Bayes-Theorems im NB-Klassifikator, verschiedene Merkmale von NB, Vor-und Nachteile von NB, Anwendung von NB diskutiert, und im letzten habe ich eine Problemaussage von Kaggle übernommen, in der es darum geht, Patienten als Diabetiker zu klassifizieren oder nicht.